大模型开发工具
| 开发步骤 | 开发工具 |
|---|---|
| 数据处理 | MinerU、LabelU、LabelLLM |
| 预训练 | |
| 微调 | |
| RAG | LlamaIndex、LangChain、AnythingLLM、Dify、RAGFlow |
| 部署 | LMDeploy、vLLM、Ollma |
| 评测 | |
| 智能体 |
1 数据处理
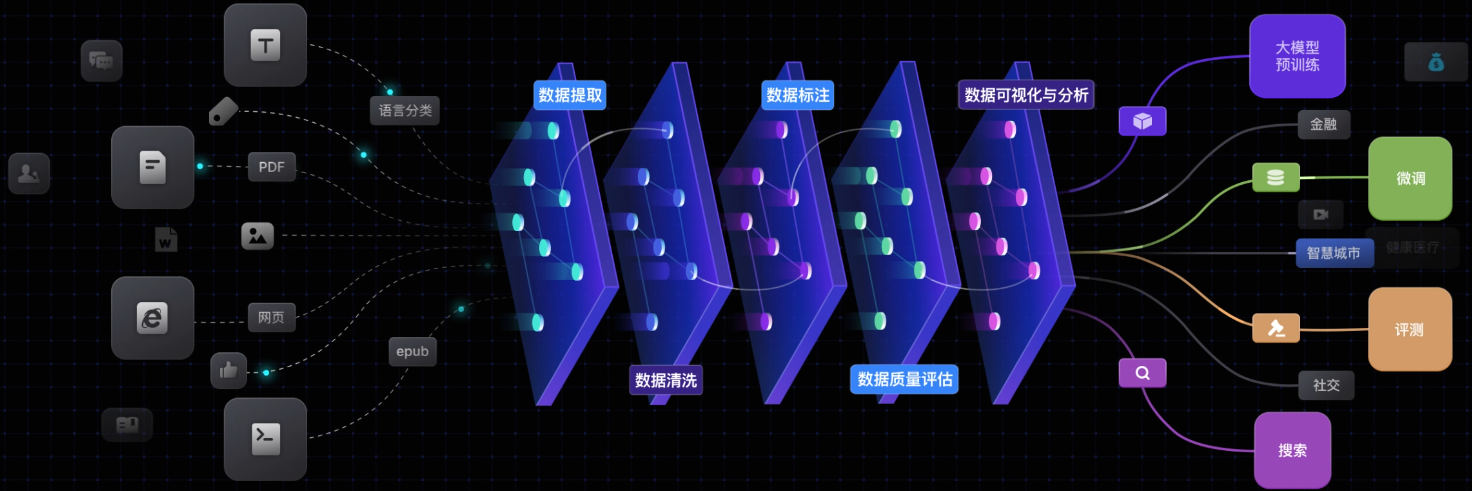
1.1 数据提取
MinerU
PDF文档提取工具
Github地址:https://github.com/opendatalab/MinerU
在线体验地址:https://opendatalab.com/OpenSourceTools/Extractor
MinerU是一款将PDF转化为机器可读格式的工具(如markdown、json),可以很方便地抽取为任意格式。
1.2 数据标注
LabelU
Github地址:https://github.com/opendatalab/labelU/tree/main
在线体验地址:https://labelu.shlab.tech/tasks/
LabelU是一款综合性的数据标注平台,专为处理多模态数据而设计。该平台旨在通过提供丰富的标注工具和高效的工作流程,帮助用户更轻松地处理图像、视频和音频数据的标注任务,满足各种复杂的数据分析和模型训练需求。
LabelLLM
Github地址:https://github.com/opendatalab/LabelLLM
LabelLLM是一个开源的数据标注平台,致力于优化对于大型语言模型(LLM)开发不可或缺的数据标注过程。LabelLLM的设计理念旨在成为独立开发者和中小型研究团队提高标注效率的有力工具。它的核心在于通过提供全面的任务管理解决方案和多样化的多模态数据支持,简化并增强模型训练的数据注释过程的效率。
2 模型微调
XTuner(4.1k)
Github地址:https://github.com/InternLM/xtuner
说明文档:https://xtuner.readthedocs.io/zh-cn/latest/index.html
XTuner是上海人工智能实验室开发的一个高效、灵活、全能的轻量化大模型微调工具库。支持多种大语言模型 LLM、多模态图文模型 VLM 的预训练及轻量级微调。
支持的模型:
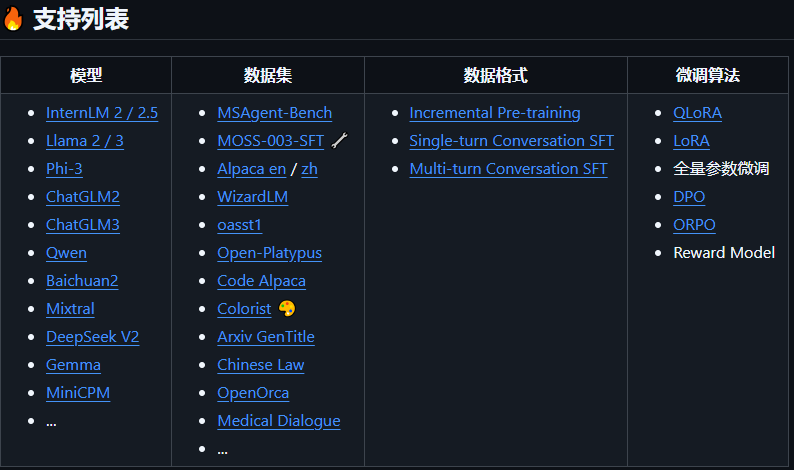
✔️
Github地址:https://github.com/modelscope/ms-swift/tree/main
说明文档:https://swift.readthedocs.io/zh-cn/latest/index.html
[ms-swift](https://github.com/modelscope/ms-swift/tree/main)(Scalable lightWeight Infrastructure for Fine-Tuning)是魔搭社区提供的大模型与多模态大模型微调部署框架,现已支持400+大模型与100+多模态大模型的训练(预训练、微调、人类对齐)、推理、评测、量化与部署。
支持的模型:
支持的模型和数据集 — swift 3.0.0.dev0 文档
LLaMA-Factory(36.8k)
模块化与易用性的完美融合
Github地址:https://github.com/hiyouga/LLaMA-Factory/tree/main
说明文档:https://llamafactory.readthedocs.io/zh-cn/latest/index.html
LLaMA Factory是一个简单易用且高效的大型语言模型(Large Language Model)训练与微调平台。通过LLaMA Factory,可以在无需编写任何代码的前提下,在本地完成上百种预训练模型的微调。
性能与效率的革命性突破
Github地址:https://github.com/unslothai/unsloth
支持的模型:https://docs.unsloth.ai/get-started/all-our-models
社区与生态的丰富
说明文档:https://hugging-face.cn/docs/transformers/index
Transformers是基于PyTorch, TensorFlow和JAX打造的领先的机器学习工具。
🤗Transformers 提供了可以轻松地下载并且训练先进的预训练模型的API和工具. 使用预训练模型可以减少计算消耗和碳排放, 并且节省从头训练所需要的时间和资源. 这些模型支持不同模态中的常见任务,比如:
📝 自然语言处理: 文本分类, 命名实体识别, 问答, 语言建模, 摘要, 翻译, 多项选择和文本生成.
🖼️ 机器视觉: 图像分类, 目标检测和语义分割.
🗣️ 音频: 自动语音识别和音频分类.
🐙 多模态: 表格问答, 光学字符识别, 从扫描文档提取信息, 视频分类和视觉问答.
🤗Transformers支持在PyTorch, TensorFlow和JAX上的互操作性. 这给在模型的每个阶段使用不同的框架带来了灵活性; 在一个框架中使用几行代码训练一个模型, 然后在另一个框架中加载它并进行推理. 模型也可以被导出为ONNX和TorchScript格式, 用于在生产环境中部署.
3 检索增强RAG
参考文档:https://zhuanlan.zhihu.com/p/697282510
✔️LlamaIndex(37.6k)
Github地址:https://github.com/jerryjliu/llama_index
说明文档:https://llama-index.readthedocs.io/zh/latest/index.html
[https://docs.llamaindex.ai/en/stable/](https://docs.llamaindex.ai/en/stable/)
LlamaIndex(GPT Index)是一个用于您的LLM应用程序的数据框架。
LlamaIndex是一个“数据框架”,可帮助您构建LLM应用程序。它提供以下工具:
- 提供数据连接器以摄取您现有的数据源和数据格式(API,PDF,文档,SQL等)
- 提供结构化您的数据(索引,图)的方法,以便可以轻松地与LLMs一起使用此数据。
- 提供高级检索/查询界面:输入任何LLM输入提示,返回检索的上下文和知识增强的输出。
- 允许与外部应用程序框架(例如LangChain,Flask,Docker,ChatGPT等)轻松集成。
LangChain(96.9k)
Github地址:https://github.com/langchain-ai/langchain
说明文档:https://python.langchain.com/docs/introduction/
[https://www.langchain.com.cn/](https://www.langchain.com.cn/)
LangChain 是一个开源工具,它提供了一种强化大型语言模型(LLM)以实现检索增强型生成的方法。该工具通过在对话模型中加入检索步骤来提升LLM的回应质量。这样的集成使得模型能够动态地从数据库或文档集合中检索信息,从而使其回应不仅更准确,而且与上下文更加相关。它将模块化和可扩展的架构与高级界面结合在一起,特别适用于构建检索增强生成(RAG)系统。
利用LangChain的功能,开发者能够开发出更智能的对话代理,这些代理能够接入并使用广泛的外部信息资源。
AnythingLLM(29.2k)
Github地址:https://github.com/Mintplex-Labs/anything-llm/tree/master
说明文档:https://docs.anythingllm.com/
AnythingLLM是一个全栈应用程序,您可以使用现成的商业大语言模型或流行的开源大语言模型,再结合向量数据库解决方案构建一个私有ChatGPT,不再受制于人:您可以本地运行,也可以远程托管,并能够与您提供的任何文档智能聊天。
✔️Dify(29.2k)
Github地址:https://github.com/Mintplex-Labs/anything-llm/tree/master
说明文档:https://docs.dify.ai/zh-hans
Dify是一款开源的大语言模型(LLM) 应用开发平台。它融合了后端即服务(Backend as Service)和 LLMOps 的理念,使开发者可以快速搭建生产级的生成式 AI 应用。即使你是非技术人员,也能参与到 AI 应用的定义和数据运营过程中。
Dify内置了构建 LLM 应用所需的关键技术栈,包括对数百个模型的支持、直观的Prompt编排界面、高质量的 RAG引擎、稳健的Agent框架、灵活的流程编排,并同时提供了一套易用的界面和API。
Github地址:https://github.com/Mintplex-Labs/anything-llm/tree/master
说明文档:https://ragflow.io/docs/dev/
RAGFlow作为一款端到端的RAG解决方案,旨在通过深度文档理解技术,解决现有RAG技术在数据处理和生成答案方面的挑战。它不仅能够处理多种格式的文档,还能够智能地识别文档中的结构和内容,从而确保数据的高质量输入。
RAGFlow的设计哲学是“高质量输入,高质量输出”,它通过提供可解释性和可控性的生成结果,让用户能够信任并依赖于系统提供的答案。