k8s知识点
k8s 笔记总结
pv
访问模式(Access Modes)
Kubernetes支持的访问模式如下。
ReadWriteOnce(RWO):读写权限,并且只能被单个Node挂 载。
ReadOnlyMany(ROX):只读权限,允许被多个Node挂载。
ReadWriteMany(RWX):读写权限,允许被多个Node挂载。
某些PV可能支持多种访问模式,但PV在挂载时只能使用一种访问模式,多种访问模式不能同时生效。
回收策略(Reclaim Policy)
Kubernetes支持的回收策略如下。
- Retain:保留数据,需要手工处理。
- Recycle:简单清除文件的操作。
- Delete:与PV相连的后端存储完成Volume的删除操作。
目前只有NFS和HostPath两种类型的PV支持Recycle策略; AWSElasticBlockStore、GCEPersistentDisk、AzureDisk和Cinder类型的PV支持Delete策略。
PV (STATUS)
在 Kubernetes 中,PersistentVolume (PV) 是一个集群级别的资源,用于表示集群中持久化存储的详细信息和状态。PV 的状态由其 STATUS 字段来表示,它反映了存储卷的当前状态。了解这些状态有助于掌握 PV 在生命周期中的位置,以及它是否能够被持久卷声明 (PersistentVolumeClaim, PVC) 使用。
以下是 Kubernetes 中 PV 的几种可能的状态:
1. Available
- 描述: 该状态表示 PV 可以被绑定到 PVC。PV 处于
Available状态时,它未被任何 PVC 使用,可以供新的 PVC 绑定。 - 特点:
- PV 还未与任何 PVC 绑定。
- 准备好用于新的 PVC 绑定。
2. Bound
- 描述: 该状态表示 PV 已经被绑定到一个 PVC,且正被 PVC 使用。
- 特点:
- PV 已经与一个 PVC 绑定。
- 它不能再被其他 PVC 绑定,直到被释放。
3. Released
- 描述: 该状态表示 PV 之前已经绑定的 PVC 已经被删除,但是 PV 本身还没有被集群中的任何新 PVC 再次使用。
- 特点:
- PVC 已被删除。
- 数据可能仍然存在于 PV 上,但它还未被新的 PVC 重新绑定。
4. Failed
- 描述: 该状态表示 PV 由于某种原因无法使用,通常是因为与 PV 相关的存储设备出现了错误或问题。
- 特点:
- PV 在操作过程中遇到错误,无法正常使用。
- 可能需要管理员干预以修复问题。
状态转换
PV 的状态转换通常遵循以下过程:
- 初始状态: PV 被创建后,处于
Available状态。 - 绑定: 一个 PVC 请求匹配 PV,PV 被绑定到 PVC 后,状态变为
Bound。 - 释放: PVC 被删除后,PV 状态变为
Released。 - 再利用或删除:
- 如果允许再利用,管理员可以手动将 PV 状态重置为
Available,使其可以绑定到新的 PVC。 - 如果 PV 被认为不再需要,可能会被删除。
- 如果允许再利用,管理员可以手动将 PV 状态重置为
状态图示
以下是状态转换的示意图:
Available
|
| PVC 绑定
V
Bound
|
| PVC 删除
V
Released
|
| 删除或再利用
V
Failed (或) AvailableResourcequotas与Limitranges
在 Kubernetes(K8s)集群中,ResourceQuotas 和 LimitRanges 是两种用于资源管理和控制的机制。它们帮助管理员确保资源的公平分配和高效利用。以下是对这两者的详细介绍:
ResourceQuotas
ResourceQuotas 是一种在 Kubernetes 中用来限制命名空间(Namespace)内资源总量的机制。它们用于防止某个命名空间消耗过多的集群资源,从而影响其他命名空间的正常运行。
作用
- 限制命名空间资源使用: ResourceQuotas 确保每个命名空间不会消耗超过指定的资源限额。
- 控制资源分配: 它们帮助管理员公平分配集群资源,防止资源耗尽。
- 提升资源管理能力: 通过设置资源限额,管理员可以更好地管理和监控资源使用情况。
配置示例
以下是一个 ResourceQuota 的 YAML 配置示例,它限制了某个命名空间内的 CPU 和内存总量,以及对象数量(如 Pod 和 Service):
apiVersion: v1
kind: ResourceQuota
metadata:
name: example-quota
namespace: example-namespace
spec:
hard:
pods: "10" # 限制 Pod 的总数量
services: "5" # 限制 Service 的总数量
requests.cpu: "4" # 限制 CPU 请求总量
requests.memory: "8Gi" # 限制内存请求总量
limits.cpu: "10" # 限制 CPU 使用总量
limits.memory: "16Gi" # 限制内存使用总量主要字段
- hard: 定义了资源的硬性限制,包括 CPU、内存、存储和对象数量等。
- scopes: 可选字段,指定了 ResourceQuota 适用的对象范围(如仅应用于某些特定的资源类型)。
使用场景
- 开发环境: 限制资源以确保测试环境不会占用过多的生产资源。
- 多租户环境: 在共享集群中,控制不同租户(命名空间)之间的资源使用。
- 成本管理: 控制资源使用来管理和控制成本。
LimitRanges
LimitRanges 是一种在 Kubernetes 中用于限制命名空间内单个 Pod 或容器资源使用的机制。与 ResourceQuotas 的整体限制不同,LimitRanges 主要控制单个 Pod 或容器的资源使用范围。
作用
- 设置默认资源限制: 如果 Pod 或容器没有指定资源请求和限制,LimitRanges 可以提供默认值。
- 防止资源过度消耗: 通过限制单个容器或 Pod 的资源使用,防止过多的资源消耗影响整个集群的性能。
- 鼓励合理的资源分配: 鼓励开发人员在部署 Pod 时合理设置资源请求和限制。
配置示例
以下是一个 LimitRange 的 YAML 配置示例,它为容器设置了 CPU 和内存的默认值和最大/最小值:
apiVersion: v1
kind: LimitRange
metadata:
name: example-limits
namespace: example-namespace
spec:
limits:
- max:
cpu: "1" # 容器的最大 CPU 使用量
memory: "1Gi" # 容器的最大内存使用量
min:
cpu: "100m" # 容器的最小 CPU 使用量
memory: "128Mi" # 容器的最小内存使用量
default:
cpu: "500m" # 容器的默认 CPU 请求量
memory: "512Mi" # 容器的默认内存请求量
defaultRequest:
cpu: "250m" # 容器的默认 CPU 请求
memory: "256Mi" # 容器的默认内存请求
type: Container # 应用类型主要字段
- max: 定义了单个容器可以请求的最大资源量。
- min: 定义了单个容器必须请求的最小资源量。
- default: 定义了容器没有指定资源请求和限制时的默认值。
- defaultRequest: 定义了容器没有指定资源请求时的默认请求值。
- type: 指定了限制适用于 Pod 还是容器。
使用场景
- 应用程序标准化: 在命名空间内强制执行资源使用标准,确保所有容器符合预期的资源使用模式。
- 资源优化: 防止资源过度配置或资源不足,从而优化集群性能和资源利用率。
- 开发与测试环境: 在不同环境中设置不同的限制,确保资源的合理分配和使用。
比较与总结
ResourceQuotas:
- 范围: 适用于整个命名空间的资源总量。
- 目的: 控制命名空间内的资源使用上限,确保集群资源的公平分配和高效利用。
- 典型场景: 多租户环境、开发环境中的资源限制。
LimitRanges:
- 范围: 适用于单个 Pod 或容器的资源使用。
- 目的: 设置资源使用的默认值和最大/最小限制,防止个体资源过度消耗。
- 典型场景: 应用程序的资源标准化和资源优化。
两者结合使用,可以在 Kubernetes 集群中提供强大的资源管理能力,确保资源的公平分配和高效使用。
k8s技能图谱
静态pod
Static Pod 是 Kubernetes 中的一种特殊类型的 Pod,它由 kubelet 直接管理,而不是通过 Kubernetes API Server 来创建和管理。Static Pod 通常用于集群管理工具(如 Kubernetes 本身)的部署和管理,尤其是在 Kubernetes 控制平面组件(如 etcd、kube-apiserver、kube-controller-manager 和 kube-scheduler)自身的管理中。
Static Pod 的特点
由 kubelet 管理:
- Static Pod 由运行在节点上的 kubelet 直接管理,不需要 API Server 的参与。
- kubelet 会定期扫描特定的目录(通常是
/etc/kubernetes/manifests)中的 Pod 定义文件,并根据这些文件创建和管理 Pod。
没有 ReplicaSet 或 Deployment:
- Static Pod 不是通过 Deployment、ReplicaSet 或其他控制器管理的,因此它们没有自动伸缩、滚动更新等高级特性。
静态配置:
- Static Pod 的配置是静态文件,通常是 JSON 或 YAML 格式,存放在节点的文件系统中。
- 这些配置文件不会因为 API Server 或 etcd 的故障而丢失,因此非常适合用于管理集群的核心组件。
自动重启:
- 如果 Static Pod 崩溃或被删除,kubelet 会根据配置文件自动重新创建它们,保证这些关键组件的高可用性。
创建 Static Pod
要创建一个 Static Pod,你需要在节点的特定目录中(通常是 /etc/kubernetes/manifests)创建一个包含 Pod 定义的 YAML 文件。以下是一个示例:
# 文件路径:/etc/kubernetes/manifests/static-pod-example.yaml
apiVersion: v1
kind: Pod
metadata:
name: static-pod-example
namespace: kube-system
spec:
containers:
- name: nginx
image: nginx:latest
ports:
- containerPort: 80将上述 YAML 文件保存到节点的 /etc/kubernetes/manifests 目录中后,kubelet 会自动检测到该文件并创建对应的 Pod。
使用场景
Static Pod 通常用于以下场景:
Kubernetes 控制平面组件:
- 部署和管理 Kubernetes 控制平面组件(如 etcd、kube-apiserver、kube-controller-manager 和 kube-scheduler),这些组件必须在集群启动时运行,不能依赖于 Kubernetes 自身来管理。
集群启动和恢复:
- 在集群启动或恢复过程中,使用 Static Pod 确保关键组件能够独立于 Kubernetes API Server 和 etcd 正常启动。
简化的节点管理:
- 在一些简化的集群管理方案中,可能会使用 Static Pod 来运行节点级别的服务或代理,而不依赖于 Kubernetes 控制器。
监控和管理
由于 Static Pod 由 kubelet 直接管理,因此它们的一些管理和监控操作与普通 Pod 略有不同:
- 日志查看:你仍然可以使用
kubectl logs命令查看 Static Pod 的日志。 - 状态检查:可以使用
kubectl get pod -n kube-system命令查看 Static Pod 的状态。 - 更新 Pod:要更新 Static Pod,需要手动编辑对应的 YAML 文件,kubelet 会自动检测到文件的变化并重新创建 Pod。
Static Pod 是 Kubernetes 提供的一种灵活机制,用于确保关键组件的高可用性和独立性,是集群稳定运行的关键保障之一。
Taint
Taint 是 Kubernetes 中的一种机制,用于限制 Pod 在节点上运行的条件。Taint 可以应用于节点,并指定一个键值对,用于限制 Pod 在节点上运行的条件。
Taint 机制
Taint 是应用在节点上的属性,表示这个节点对某些 Pod 来说是不合适的。每个 Taint 由三个部分组成:
- 键(Key):标识 Taint 的名称。
- 值(Value):标识 Taint 的具体值。
- 效果(Effect):标识 Taint 的作用方式。常见的效果有三种:
NoSchedule:新的 Pod 不会被调度到这个节点上。PreferNoSchedule:尽量避免将新的 Pod 调度到这个节点上,但如果没有其他合适的节点,也可能会调度。NoExecute:已经运行在这个节点上的 Pod 会被驱逐,新 Pod 也不会被调度到这个节点上。
节点设置taint
kubectl taint no minikube level=high:NoSchedule移除 Taint
kubectl taint no minikube level=high:NoSchedule-Pod设置toleration
apiVersion: apps/v1 kind: Deployment metadata: name: nginx spec: replicas: 1 selector: matchLabels: app: nginx template: metadata: labels: app: nginx spec: containers: - name: nginx command: ["python3"] args: ["-m", "http.server", "9999"] image: "registry.cnbita.com:5000/wangshi/python:3.10" imagePullPolicy: IfNotPresent ports: - name: http containerPort: 80 protocol: TCP resources: requests: cpu: 100m memory: 128Mi limits: cpu: 500m memory: 256Mi tolerations: - key: "level" operator: "Equal" value: "high" effect: "NoSchedule"
上述配置说明pod能够容忍节点设置taint的level=high:NoSchedule,如果pod不设置亲和性tolerations,则无法进行部署。如下所示:
Tolerations: node.kubernetes.io/not-ready:NoExecute op=Exists for 300s
node.kubernetes.io/unreachable:NoExecute op=Exists for 300s
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Warning FailedScheduling 3m57s default-scheduler 0/1 nodes are available: 1 node(s) had untolerated taint {level: high}. preemption: 0/1 nodes are available: 1 Preemption is not helpful for scheduling..在 Kubernetes 中,taint 是用于节点管理的机制,通过标记节点来影响 Pod 的调度。Taints 可以防止某些 Pod 调度到特定节点上,除非这些 Pod 具有相应的 toleration。这种机制有助于确保工作负载在集群中得到更好地分布和隔离。
无头服务(Headless Services)
在 Kubernetes 中,Headless Service 是一种特殊类型的 Service,不会分配集群 IP(ClusterIP)。这种服务类型主要用于暴露 StatefulSet 的每个 Pod,并且允许直接访问每个 Pod。下面是对 Kubernetes Headless Service 的详细介绍:
Headless Service 的特点
没有 Cluster IP:
- 与普通的 Kubernetes Service 不同,Headless Service 不会为服务分配一个 Cluster IP。它通过将
ClusterIP字段设置为None来实现这一点。
- 与普通的 Kubernetes Service 不同,Headless Service 不会为服务分配一个 Cluster IP。它通过将
直接访问 Pod:
- Headless Service 允许客户端直接访问服务后端的每个 Pod,而不是通过负载均衡器来访问。这对于需要直接与特定 Pod 进行通信的场景非常有用,例如 StatefulSet 中的数据库分片或有状态应用。
DNS 解析:
- Headless Service 会为每个 Pod 创建一个 DNS 记录,这样客户端可以通过 DNS 名称直接访问特定的 Pod。对于 StatefulSet,每个 Pod 都有一个稳定的 DNS 名称。
使用场景
Headless Service 主要用于以下几种场景:
StatefulSet:
- StatefulSet 通常用于部署有状态应用,例如数据库集群或分布式文件系统。Headless Service 允许这些有状态应用中的各个 Pod 直接相互访问。
自定义服务发现:
- 在某些情况下,应用需要自定义的服务发现机制,而不是 Kubernetes 提供的负载均衡。Headless Service 允许应用自行管理和发现服务实例。
Headless Service 的定义示例
以下是一个 Headless Service 的 YAML 定义示例:
apiVersion: v1
kind: Service
metadata:
name: headless-service
namespace: default
spec:
clusterIP: None
selector:
app: my-app
ports:
- name: http
port: 80
targetPort: 8080这个示例定义了一个名为 headless-service 的服务,没有 ClusterIP。它选择了带有标签 app: my-app 的 Pod,并将流量从服务的 80 端口转发到 Pod 的 8080 端口。
StatefulSet 与 Headless Service 的结合
以下是一个使用 Headless Service 的 StatefulSet 示例:
定义 Headless Service
apiVersion: v1
kind: Service
metadata:
name: my-stateful-service
namespace: default
spec:
clusterIP: None
selector:
app: my-stateful-app
ports:
- name: http
port: 80
targetPort: 8080定义 StatefulSet
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: my-stateful-app
namespace: default
spec:
serviceName: "my-stateful-service"
replicas: 3
selector:
matchLabels:
app: my-stateful-app
template:
metadata:
labels:
app: my-stateful-app
spec:
containers:
- name: my-container
image: my-image
ports:
- containerPort: 8080在这个例子中,my-stateful-service 是一个 Headless Service,它与 my-stateful-app StatefulSet 结合使用。每个 StatefulSet Pod 都有一个稳定的 DNS 名称,例如 my-stateful-app-0.my-stateful-service.default.svc.cluster.local。
总结
Headless Service 是 Kubernetes 中的一种特殊服务类型,适用于需要直接访问每个 Pod 的场景。它通过不分配 Cluster IP 来实现这一点,并为每个 Pod 提供稳定的 DNS 记录。Headless Service 通常用于有状态应用和自定义服务发现场景,尤其是在 StatefulSet 中。
Kubelet的hairpin-mode
Kubelet 的 hairpin-mode 是一个配置选项,它决定了 Pod 内的容器是否能够通过 Pod 的 IP 访问自身以及同一 Pod 中的其他容器的服务。这种访问模式被称为“发夹模式(Hairpin Mode)”。具体来说,hairpin-mode 的作用是在容器网络接口上设置发夹规则,使得流量可以从容器发出后,又从同一个网络接口回到容器内部。
Hairpin Mode 的工作原理
在发夹模式下,容器内的应用可以通过服务 IP 或者 Pod IP 访问同一 Pod 内的其他容器。这种模式主要用于以下情况:
- 自访问:容器需要通过 Pod IP 访问自己,例如某些服务需要通过自身的外部 IP 进行健康检查。
- 内部通信:同一个 Pod 内的多个容器之间的通信,通过 Pod 的网络接口实现内循环。
配置 hairpin-mode
Kubelet 提供了几个选项来配置 hairpin-mode:
hairpin-veth:启用发夹模式,这是默认模式。Kubelet 会在创建容器网络接口时启用发夹规则。promiscuous-bridge:使用混杂模式的网桥。这种模式在性能上可能有一些开销,但在某些网络插件或环境下可能是必要的。none:禁用发夹模式。这种模式下,容器无法通过 Pod IP 访问自身或同一 Pod 内的其他容器。
配置示例
要配置 hairpin-mode,可以在 Kubelet 的启动参数中设置。例如,在 kubelet 配置文件中:
apiVersion: kubelet.config.k8s.io/v1beta1
kind: KubeletConfiguration
hairpinMode: hairpin-veth或者在启动 Kubelet 时通过命令行参数:
kubelet --hairpin-mode=hairpin-veth使用场景
- 服务自身健康检查:某些服务需要通过 Pod IP 对自身进行健康检查。
- 同一 Pod 内的容器通信:Pod 内部的不同容器通过 Pod IP 进行通信,简化网络配置。
总结
hairpin-mode 是 Kubelet 的一个重要配置选项,用于控制容器是否能够通过 Pod IP 进行自访问和内部通信。根据具体的应用场景和需求,可以选择适当的发夹模式配置。常见的选择是默认的 hairpin-veth 模式,它能够在大多数场景下提供良好的性能和功能支持。
资源短缺
QoS 划分的主要应用场景,是当宿主机资源紧张的时候,kubelet 对 Pod 进行 Eviction(即资源回收)时需要用到的。
具体地说,当 Kubernetes 所管理的宿主机上不可压缩资源短缺时,就有可能触发 Eviction。比如,可用内存(memory.available)、可用的宿主机磁盘空间(nodefs.available),以及容器运行时镜像存储空间(imagefs.available)等等。
目前,Kubernetes 为你设置的 Eviction 的默认阈值如下所示:
memory.available<100Mi
nodefs.available<10%
nodefs.inodesFree<5%
imagefs.available<15%上述各个触发条件在 kubelet 里都是可配置的
kubelet --eviction-hard=imagefs.available<10%,memory.available<500Mi,nodefs.available<5%,nodefs.inodesFree<5% --eviction-soft=imagefs.available<30%,nodefs.available<10% --eviction-soft-grace-period=imagefs.available=2m,nodefs.available=2m --eviction-max-pod-grace-period=600Eviction 在 Kubernetes 里其实分为 Soft 和 Hard 两种模式。
其中,Soft Eviction 允许你为 Eviction 过程设置一段“优雅时间”,比如上面例子里的 imagefs.available=2m,就意味着当 imagefs 不足的阈值达到 2 分钟之后,kubelet 才会开始 Eviction 的过程。
而 Hard Eviction 模式下,Eviction 过程就会在阈值达到之后立刻开始。
Kubernetes 计算 Eviction 阈值的数据来源,主要依赖于从 Cgroups 读取到的值,以及使用 cAdvisor 监控到的数据。
Pod 的 QoS 类别: Guaranteed > Burstable > BestEffort
Kubernetes 会保证只有当 Guaranteed 类别的 Pod 的资源使用量超过了其 limits 的限制,或者宿主机本身正处于 Memory Pressure 状态时,Guaranteed 的 Pod 才可能被选中进行 Eviction 操作。
如何能够让 Kubernetes 的调度器尽可能地将 Pod 分布在不同机器上,避免“堆叠”呢?
在 Kubernetes 中,可以通过以下几种方式配置调度策略,以尽可能地将 Pod 分布在不同的节点上,避免“堆叠”:
1. Pod 反亲和性(Pod Anti-Affinity)
Pod 反亲和性是一种调度约束,允许用户指定某些 Pod 不应该与其他特定 Pod 运行在同一个节点上。
示例
apiVersion: v1
kind: Pod
metadata:
name: example-pod
spec:
affinity:
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: app
operator: In
values:
- myapp
topologyKey: "kubernetes.io/hostname"在这个示例中,podAntiAffinity 指定了具有相同标签 app=myapp 的 Pod 不应该被调度到相同的节点上。topologyKey 为 kubernetes.io/hostname,表示约束作用在节点级别。
2. 节点亲和性(Node Affinity)
Node Affinity 允许调度器根据节点标签选择合适的节点。这可以用于避免将所有 Pod 调度到相同的节点。
示例
apiVersion: v1
kind: Pod
metadata:
name: example-pod
spec:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: disktype
operator: In
values:
- ssd这个示例展示了如何使用节点标签(disktype=ssd)进行调度,以确保 Pod 被调度到带有特定标签的节点上。
3. 分布式调度策略(Spread Constraints)
Kubernetes 1.18 引入了 TopologySpreadConstraints,允许用户定义分布式调度策略,确保 Pod 均匀地分布在集群的不同节点上。
示例
apiVersion: v1
kind: Pod
metadata:
name: example-pod
spec:
topologySpreadConstraints:
- maxSkew: 1
topologyKey: kubernetes.io/hostname
whenUnsatisfiable: DoNotSchedule
labelSelector:
matchLabels:
app: myapp
containers:
- name: my-container
image: my-image在这个示例中,topologySpreadConstraints 指定 Pod 应该均匀地分布在不同的节点上。maxSkew 表示同一节点上的 Pod 数量与其他节点上的最大偏差不超过1。
4. 自定义调度器策略(Custom Scheduler Policies)
Kubernetes 允许使用自定义调度策略文件来自定义调度行为。例如,可以设置 EvenPodsSpreadPriority 来实现均匀调度。
示例
自定义调度策略文件(scheduler-policy-config.json):
{
"kind": "Policy",
"apiVersion": "v1",
"priorities": [
{
"name": "EvenPodsSpreadPriority",
"weight": 1
}
]
}启动调度器时使用该策略文件:
kube-scheduler --policy-config-file=scheduler-policy-config.json通过配置这些策略,可以显著改善 Pod 在集群中的分布情况,避免“堆叠”问题,实现资源的更高效利用。
kubelet如何实现 exec、logs 等接口
gRPC 接口调用期间,kubelet 需要跟容器项目维护一个长连接来传输数据。这种 API,我们就称之为 Streaming API。
CRI shim 里对 Streaming API 的实现,依赖于一套独立的 Streaming Server 机制。
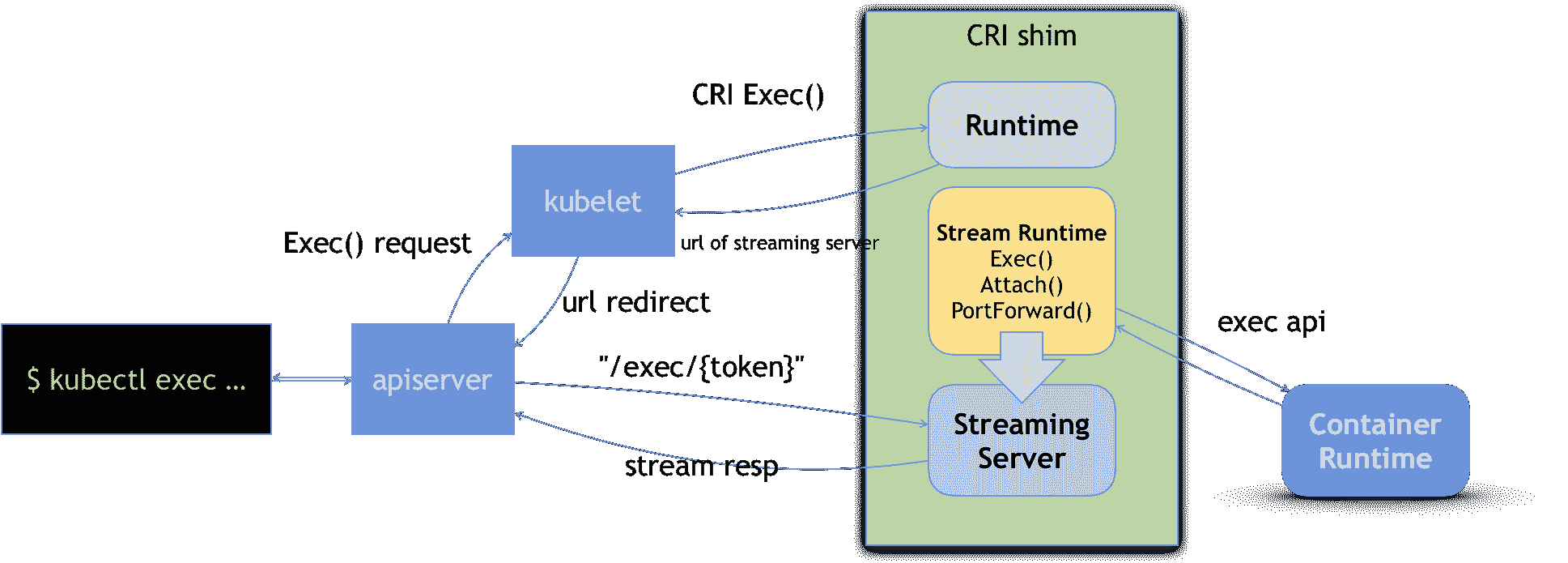
可以看到,当我们对一个容器执行 kubectl exec 命令的时候,这个请求首先交给 API Server,然后 API Server 就会调用 kubelet 的 Exec API。
这时,kubelet 就会调用 CRI 的 Exec 接口,而负责响应这个接口的,自然就是具体的 CRI shim。
但在这一步,CRI shim 并不会直接去调用后端的容器项目(比如 Docker )来进行处理,而只会返回一个 URL 给 kubelet。这个 URL,就是该 CRI shim 对应的 Streaming Server 的地址和端口。
而 kubelet 在拿到这个 URL 之后,就会把它以 Redirect 的方式返回给 API Server。所以这时候,API Server 就会通过重定向来向 Streaming Server 发起真正的 /exec 请求,与它建立长连接
当然,这个 Streaming Server 本身,是需要通过使用 SIG-Node 为你维护的 Streaming API 库来实现的。并且,Streaming Server 会在 CRI shim 启动时就一起启动。此外,Stream Server 这一部分具体怎么实现,完全可以由 CRI shim 的维护者自行决定。比如,对于 Docker 项目来说,dockershim 就是直接调用 Docker 的 Exec API 来作为实现的。
集群安装
kubeadm init --cri-socket unix:///var/run/cri-dockerd.sock
kubeadm reset --cri-socket unix:///var/run/cri-dockerd.sock
解决
l 29 15:07:31 DESKTOP-P54EAF3 kubelet[3437386]: I0729 15:07:31.604995 3437386 server.go:469] "Golang settings" GOGC="" GOMAXPROCS="" GOTRACEBACK=""
Jul 29 15:07:31 DESKTOP-P54EAF3 kubelet[3437386]: I0729 15:07:31.605172 3437386 server.go:895] "Client rotation is on, will bootstrap in background"
Jul 29 15:07:31 DESKTOP-P54EAF3 kubelet[3437386]: I0729 15:07:31.607274 3437386 certificate_store.go:130] Loading cert/key pair from "/var/lib/kubelet/pki/kubelet-client-current.pem".
Jul 29 15:07:31 DESKTOP-P54EAF3 kubelet[3437386]: I0729 15:07:31.608035 3437386 dynamic_cafile_content.go:157] "Starting controller" name="client-ca-bundle::/etc/kubernetes/pki/ca.crt"
Jul 29 15:07:31 DESKTOP-P54EAF3 kubelet[3437386]: W0729 15:07:31.611818 3437386 sysinfo.go:203] Nodes topology is not available, providing CPU topology
Jul 29 15:07:31 DESKTOP-P54EAF3 kubelet[3437386]: I0729 15:07:31.619656 3437386 server.go:725] "--cgroups-per-qos enabled, but --cgroup-root was not specified. defaulting to /"
Jul 29 15:07:31 DESKTOP-P54EAF3 kubelet[3437386]: E0729 15:07:31.619995 3437386 run.go:74] "command failed" err="failed to run Kubelet: running with swap on is not supported, please disable swap! or set --fail-swap-on flag to false. /proc/swaps contained: [Filename\t\t\t\tType\t\tSize\t\tUsed\t\tPriority /dev/sdb partition\t4194304\t\t8580\t\t-2]"
Jul 29 15:07:31 DESKTOP-P54EAF3 systemd[1]: kubelet.service: Main process exited, code=exited, status=1/FAILURE
Jul 29 15:07:31 DESKTOP-P54EAF3 systemd[1]: kubelet.service: Failed with result 'exit-code'.