Kubeflow 简介
k8s 云原生之Kubeflow 简介
官网
https://www.kubeflow.org/docs/started/introduction/
介绍
Kubeflow 简介 Kubeflow 项目致力于让机器学习 (ML) 工作流在 Kubernetes 上的部署变得简单、可移植且可扩展。我们的目标不是重新创建其他服务,而是提供一种简单的方法,将最佳的 ML 开源系统部署到各种基础设施中。只要您运行 Kubernetes,就可以运行 Kubeflow。 下图展示了主要的 Kubeflow 组件,涵盖 Kubernetes 之上 ML 生命周期的每个步骤。 
Kubeflow 架构概述
Kubeflow 是一个面向想要构建和试验 ML 管道的数据科学家的平台。Kubeflow 还适用于想要将 ML 系统部署到各种环境以进行开发、测试和生产级服务的 ML 工程师和运营团队。
概念概述
Kubeflow 是_Kubernetes 的 ML 工具包_。 下图展示了 Kubeflow 作为在 Kubernetes 之上安排 ML 系统组件的平台: 
Pipeline
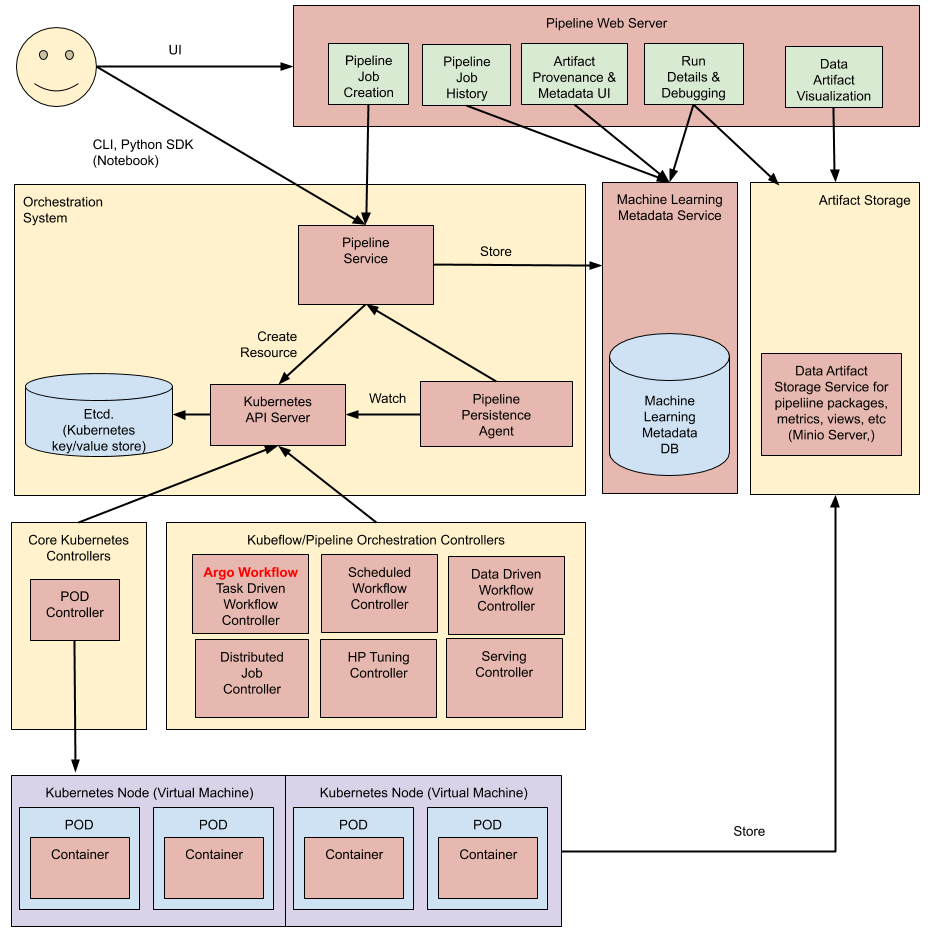 在高层次上,管道的执行过程如下:
在高层次上,管道的执行过程如下:
Python SDK:
使用Kubeflow Pipelines特定领域语言(DSL)创建组件或指定管道。
DSL compiler:
DSL编译器将您的管道的Python代码转换为静态配置(YAML)。
Pipeline Service:
调用管道服务以从静态配置创建管道运行。
Kubernetes resources:
管道服务调用Kubernetes API服务器以创建运行管道所需的必要Kubernetes资源(CRD)。
Orchestration controllers:
一组编排控制器执行完成管道所需的容器。这些容器在虚拟机上的Kubernetes Pod中执行。一个示例控制器是Argo Workflow控制器,它编排基于任务的工作流。
Artifact storage:
Pod存储两种类型的数据:
- Metadata:实验、作业、管道运行和单个标量指标。度量数据被聚合用于排序和过滤。Kubeflow Pipelines将元数据存储在MySQL数据库中。
- Artifacts:管道包、视图和大规模指标(时间序列)。使用大规模指标来调试管道运行或调查单个运行的性能。Kubeflow Pipelines将工件存储在像Minio服务器或Cloud Storage之类的工件存储中。
MySQL数据库和Minio服务器都由Kubernetes持久卷子系统支持。
Persistence agent and ML metadata:
管道持久性代理监视管道服务创建的Kubernetes资源,并将这些资源的状态持久化到ML元数据服务中。管道持久性代理记录已执行的容器集合及其输入和输出。输入/输出包括容器参数或数据工件URI。
Pipeline web server:
管道Web服务器从各种服务中收集数据以显示相关视图:当前运行的管道列表、管道执行历史记录、数据工件列表、有关单个管道运行的调试信息、有关单个管道运行的执行状态。
关键概念
Pipeline
在 Kubeflow Pipelines 中,管道是对机器学习(ML)工作流的描述,包括工作流中的所有组件及其相互关系,以图的形式呈现。管道配置包括运行管道所需的输入(参数)的定义,以及每个组件的输入和输出。 当你运行一个管道时,系统会启动一个或多个 Kubernetes Pod,这些 Pod 对应于工作流(管道)中的各个步骤(组件)。这些 Pod 会启动 Docker 容器,而容器则会启动你的程序。 开发完成管道后,你可以使用 Kubeflow Pipelines UI 或 Kubeflow Pipelines SDK 上传你的管道。
Component
在 Kubeflow Pipelines 中,组件是一个独立的代码集,它执行机器学习(ML)工作流(管道)中的某一步骤,例如数据预处理、数据转换、模型训练等。组件类似于函数,具有名称、参数、返回值和主体。
组件代码
每个组件的代码包括以下部分:
- 客户端代码:与端点通信以提交作业的代码。例如,与 Google Dataproc API 通信以提交 Spark 作业的代码。
- 运行时代码:执行实际作业的代码,通常在集群中运行。例如,将原始数据转换为预处理数据的 Spark 代码。
关于客户端代码和运行时代码的命名约定——对于名为“mytask”的任务:
mytask.py程序包含客户端代码。mytask目录包含所有运行时代码。
组件定义
用 YAML 格式的组件规范描述 Kubeflow Pipelines 系统中的组件。组件定义包括以下部分:
- 元数据:名称、描述等。
- 接口:输入/输出规范(名称、类型、描述、默认值等)。
- 实现:描述在给定组件输入参数值的情况下如何运行组件的规范。实现部分还描述了组件完成运行后如何获取输出值。
有关组件的完整定义,请参见组件规范。
容器化组件
你必须将组件打包为 Docker 镜像。组件代表容器内的特定程序或入口点。 管道中的每个组件独立执行。组件不会在同一进程中运行,也不能直接共享内存数据。你必须将传递给组件之间的数据序列化(转换为字符串或文件),以便数据可以在分布式网络上传输。然后,必须反序列化这些数据以供下游组件使用。
Graph
在 Kubeflow Pipelines 中,图(Graph)是管道运行时在 Kubeflow Pipelines UI 中的图形表示。图显示了管道运行已执行或正在执行的步骤,箭头指示了管道组件之间的父/子关系。运行一开始,就可以查看这个图。图中的每个节点对应管道中的一个步骤,并进行相应的标注。 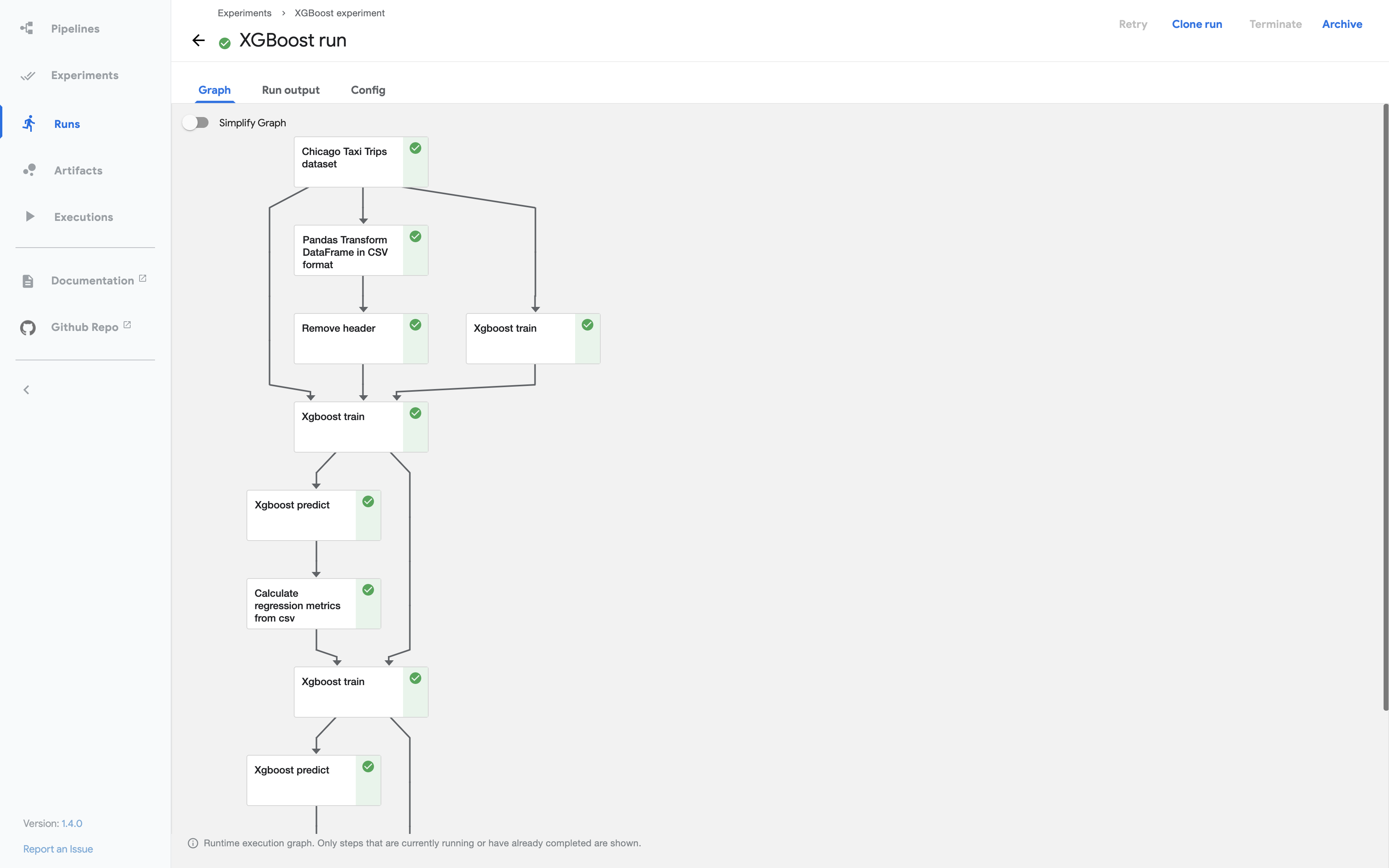 每个节点的右上角有一个图标,指示其状态:运行中(running)、成功(succeeded)、失败(failed)或跳过(skipped)。当节点的父节点包含条件语句时,节点可能会被跳过。
每个节点的右上角有一个图标,指示其状态:运行中(running)、成功(succeeded)、失败(failed)或跳过(skipped)。当节点的父节点包含条件语句时,节点可能会被跳过。
Experiment
实验是一个工作空间,你可以在其中尝试管道的不同配置。你可以使用实验将你的运行组织成逻辑组。实验可以包含任意的运行,包括定期运行。
Run and Recurring Run
一次运行(run)是对管道的单次执行。运行包含你尝试的所有实验的不可变日志,设计为自包含的,以便于重现。你可以通过查看 Kubeflow Pipelines UI 上的运行详情页面来跟踪运行的进度,在那里你可以看到运行时的图表、输出工件和每个步骤的日志。 定期运行(recurring run)或在 Kubeflow Pipelines 后端 API 中称为作业(job),是管道的可重复运行。定期运行的配置包括指定所有参数值的管道副本和运行触发器。你可以在任何实验中启动定期运行,它会定期启动运行配置的新副本。你可以从 Kubeflow Pipelines UI 启用/禁用定期运行。你还可以指定最大并发运行数,以限制并行启动的运行数量。如果管道预计运行时间较长且触发频繁运行,这会很有帮助。
Run Trigger
运行触发器是一个标志,用于告知系统何时生成新的定期运行配置。可用的运行触发器类型包括:
- 周期性(Periodic):基于时间间隔调度运行(例如:每2小时或每45分钟)。
- Cron:使用 cron 语法调度运行。
Step
步骤(step)是管道中某个组件的执行。步骤与其组件之间的关系是一种实例化关系,类似于运行与其管道之间的关系。在复杂的管道中,组件可以在循环中多次执行,或在解析管道代码中的 if/else 类似子句后有条件地执行。
Output Artifact
输出工件(output artifact)是由管道组件发出的输出,Kubeflow Pipelines UI 能理解并呈现为丰富的可视化内容。包括工件在内的管道组件非常有用,因为它们可以用于性能评估、快速决策或不同运行间的比较。工件还使得理解管道各个组件的工作方式成为可能。工件可以是简单的文本数据视图,也可以是丰富的交互式可视化。
ML Metadata
注意:Kubeflow Pipelines 已从使用 kubeflow/metadata 转向使用 google/ml-metadata 作为元数据依赖。 Kubeflow Pipelines 后端将管道运行的运行时信息存储在元数据存储中。运行时信息包括任务的状态、工件的可用性、与执行或工件关联的自定义属性等。了解更多信息,请参阅 ML Metadata 入门指南。 如果一个工件被多个不同运行中的执行使用,你可以查看跨管道运行的工件和执行之间的连接。这种连接可视化称为谱系图(Lineage Graph)。
Choosing an Argo Workflows Executor
Argo 工作流执行器是一个符合特定接口的进程,使 Argo 能够执行某些操作,如监控 Pod 日志、收集工件、管理容器生命周期等。 Kubeflow Pipelines 使用 Argo Workflows 作为工作流引擎,因此 Kubeflow Pipelines 用户需要选择一个工作流执行器。
主要的 Argo 工作流执行器类型包括:
- K8sAPIExecutor:通过 Kubernetes API 直接与集群交互,执行和监控容器。这是默认的执行器,适用于大多数场景。
- PNSExecutor:通过共享的进程命名空间(Process Namespace Sharing),使主容器可以访问子容器的文件系统和进程。这对于需要在容器之间共享数据的工作流特别有用。
- EmissaryExecutor:基于 Emissary-Ingress,专为高效的文件操作和网络操作设计,适用于需要高效处理大量小文件的工作流。 自 2022 年 2 月 Kubeflow Pipelines 1.8 正式发布以来,Emissary 执行器一直是 Kubeflow Pipelines 的默认执行器。
- DockerExecutor:直接与 Docker 守护进程交互来管理容器。这种方法依赖于 Docker,在某些 Kubernetes 配置中可能不适用。
如何选择适合的执行器:
选择合适的工作流执行器取决于工作流的具体需求和集群环境:
- 默认选择 K8sAPIExecutor:如果你的工作流不需要特别的资源共享或文件处理,默认的 K8sAPIExecutor 通常是最合适的选择。
- 选择 PNSExecutor:如果你的工作流步骤之间需要共享文件或进程命名空间,那么 PNSExecutor 是一个好的选择。
- 选择 EmissaryExecutor:如果你的工作流需要高效处理大量文件操作,尤其是小文件,可以选择 EmissaryExecutor。
- 选择 DockerExecutor:如果你更熟悉 Docker 并且你的集群配置支持 Docker,可以考虑 DockerExecutor,但要注意其兼容性问题。
注意,Argo Workflows 支持其他工作流执行器,但 Kubeflow Pipelines 团队仅推荐在 Emissary 执行器和 Docker 执行器之间进行选择。在配置 Kubeflow Pipelines 时,用户可以根据具体需求和工作流特点选择合适的 Argo 工作流执行器,以优化管道的执行效率和资源管理。
组件详细介绍
[root@yigou-stg-101-61 ~]# kubectl get po -n kubeflow
NAME READY STATUS RESTARTS AGE
controller-manager-78d9bcc678-bgwtr 1/1 Running 0 17h
katib-controller-7d7dffdb8f-7c6vk 1/1 Running 0 17h
katib-db-manager-77d684cf4-tqtgh 1/1 Running 0 17h
katib-ui-849479cf5f-rgmgf 1/1 Running 0 17h
metadata-grpc-deployment-66457c4745-q9ddn 1/1 Running 0 17h
metadata-writer-9956596d8-92g5h 1/1 Running 0 17h
ml-pipeline-7cc7c5b47-k8r6z 1/1 Running 1 (17h ago) 17h
ml-pipeline-persistenceagent-6c686b5b54-9bzwq 1/1 Running 0 17h
ml-pipeline-scheduledworkflow-d894ffcd8-65j6h 1/1 Running 0 17h
ml-pipeline-ui-57dbbdfd77-5bbh9 1/1 Running 0 17h
ml-pipeline-viewer-crd-86868f775c-thcd8 1/1 Running 0 17h
ml-pipeline-visualizationserver-5499555669-fsgks 1/1 Running 0 17h
workflow-controller-799c5f4b48-nv8km 1/1 Running 0 17h下面是每个 Pod 的功能简介:
- controller-manager-78d9bcc678-bgwtr:
- 控制器管理器 Pod,负责管理 Kubernetes 集群中的控制器,如 ReplicaSet、Deployment 等。
- katib-controller-7d7dffdb8f-7c6vk:
- Katib 控制器 Pod,是 Katib(超参数调优工具)的控制器组件,负责管理和调度超参数搜索任务。
- katib-db-manager-77d684cf4-tqtgh:
- Katib 数据库管理器 Pod,负责管理 Katib 的数据库,存储超参数调优任务的状态和结果。
- katib-ui-849479cf5f-rgmgf:
- Katib 用户界面 Pod,提供 Katib 的 Web 用户界面,用于查看和监控超参数调优任务的状态和结果。
- metadata-grpc-deployment-66457c4745-q9ddn:
- 元数据 gRPC 服务 Pod,提供 Kubernetes 元数据服务,允许用户在 Kubeflow Pipelines 中创建和管理元数据。
- metadata-writer-9956596d8-92g5h:
- 元数据写入器 Pod,负责将元数据写入到存储后端,与元数据 gRPC 服务一起用于 Kubeflow Pipelines。
- ml-pipeline-7cc7c5b47-k8r6z:
- ML Pipeline Pod,是 Kubeflow Pipelines 的核心组件之一,提供了机器学习工作流的定义、运行和监控功能。
- registry.cnbita.com:5000/kubeflow-pipelines/api-server
- backend/src/apiserver
- backend\Dockerfile
- ml-pipeline-persistenceagent-6c686b5b54-9bzwq:
- ML Pipeline 持久化代理 Pod,负责管理 Kubeflow Pipelines 的持久化存储,存储工作流定义和执行状态。
- ml-pipeline-scheduledworkflow-d894ffcd8-65j6h:
- ML Pipeline 定时工作流 Pod,负责调度和执行 Kubeflow Pipelines 中的定时任务。
- ml-pipeline-ui-57dbbdfd77-5bbh9:
- ML Pipeline 用户界面 Pod,提供 Kubeflow Pipelines 的 Web 用户界面,用于创建、运行和监控机器学习工作流。
- ml-pipeline-viewer-crd-86868f775c-thcd8:
- ML Pipeline 视图 CRD Pod,用于自定义 Kubeflow Pipelines 中的自定义资源定义(CRD)的展示。
- ml-pipeline-visualizationserver-5499555669-fsgks:
- ML Pipeline 可视化服务器 Pod,提供 Kubeflow Pipelines 的可视化服务,用于展示机器学习工作流的执行状态和结果。
- workflow-controller-799c5f4b48-nv8km:
- 工作流控制器 Pod,是 Kubeflow Pipelines 的控制器组件之一,负责管理和执行工作流任务。
这些 Pod 组成了 Kubeflow 中的各个核心组件,提供了从超参数调优到机器学习工作流管理的完整功能。这些 Pod 之间有一定的关联关系,它们共同组成了 Kubeflow 平台,用于支持机器学习工作流的定义、运行、监控和优化。以下是它们之间的一些主要关联关系:
- 控制器管理器 (controller-manager):
- 负责管理 Kubernetes 集群中的各种控制器,确保其他 Pod 和服务正常运行。
- Katib 组件:
- katib-controller:管理和调度超参数调优任务。
- katib-db-manager:管理存储 Katib 数据的数据库。
- katib-ui:提供 Katib 的 Web 用户界面。
- Katib 的各个组件通过数据库和控制器进行通信和协调,共同实现超参数调优功能。
- 元数据服务 (metadata-grpc-deployment 和 metadata-writer):
- metadata-grpc-deployment:提供 gRPC 接口,用于管理元数据。
- metadata-writer:负责将元数据写入到持久化存储中。
- 这些组件通过元数据存储和 gRPC 接口进行通信,支持 Kubeflow Pipelines 中的元数据管理。
- Kubeflow Pipelines 组件:
- ml-pipeline:核心组件,负责机器学习工作流的定义、运行和监控。
- ml-pipeline-persistenceagent:管理工作流的持久化存储。
- ml-pipeline-scheduledworkflow:调度和执行定时任务。
- ml-pipeline-ui:提供 Web 用户界面,允许用户交互和监控工作流。
- ml-pipeline-viewer-crd:展示自定义资源定义(CRD)。
- ml-pipeline-visualizationserver:提供工作流执行状态和结果的可视化。
- 这些组件通过存储系统、API 和用户界面进行紧密集成,形成完整的机器学习工作流管理平台。
- 工作流控制器 (workflow-controller):
- 负责管理和执行工作流任务,确保工作流按照定义的步骤顺利执行。
- 与 Kubeflow Pipelines 组件紧密合作,管理和协调工作流的各个部分。
总体而言,这些 Pod 通过 Kubernetes 集群中的服务和控制器进行通信和协调,共同提供了一个功能强大的机器学习工作流管理平台。
controller-manager
apiVersion: apps/v1
kind: Deployment
metadata:
name: controller-manager
labels:
control-plane: controller-manager
controller-tools.k8s.io: "1.0"
spec:
selector:
matchLabels:
control-plane: controller-manager
controller-tools.k8s.io: "1.0"
template:
metadata:
labels:
control-plane: controller-manager
controller-tools.k8s.io: "1.0"
spec:
containers:
- command:
- /kube-app-manager
# Built from https://github.com/kubernetes-sigs/application master branch on the date specified in the image tag.
image: gcr.io/ml-pipeline/application-crd-controller:20231101
imagePullPolicy: IfNotPresent
name: manager
env:
- name: NAMESPACE
valueFrom:
fieldRef:
fieldPath: metadata.namespace
resources:
limits:
cpu: 100m
memory: 30Mi
requests:
cpu: 100m
memory: 20Mi
serviceAccountName: application官网地址
https://github.com/kubernetes-sigs/application
Kubernetes 应用程序
Kubernetes 是一个开源系统,用于自动化部署、扩展和管理容器化应用程序。 上述描述来自 Kubernetes 主页,主要集中在容器化应用程序上。然而,Kubernetes 的元数据、对象和可视化(例如在 Dashboard 中)都集中在容器基础设施上,而不是应用程序本身。 本项目中的应用程序 CRD(自定义资源定义)和控制器旨在改变这种状况,使其能够在众多支持工具之间实现互操作。
它提供了:
- 描述应用程序元数据的能力(例如,运行一个像 WordPress 这样的应用程序)
- 一个连接基础设施(例如 Deployments)的根对象。这对于将各种资源联系在一起甚至清理(即垃圾回收)很有用
- 为支持应用程序提供信息,帮助它们查询和理解支持应用程序的对象
- 应用程序级别的健康检查
这可以被以下用户使用:
- 希望以应用程序为中心进行操作的应用程序运营商
- 像 Helm 这样的工具,它们将其软件包发布集中在应用程序安装上,并且希望与其他工具(例如 Dashboard)实现互操作
- 希望可视化应用程序(不仅仅是基础设施视图)的 Dashboards
目标
- 提供一个用于在 Kubernetes 中创建、查看和管理应用程序的标准 API。
- 提供通过
kubectl与应用程序 API 交互的 CLI 实现。 - 提供应用程序的安装状态和垃圾回收。
- 提供一种标准方式,使应用程序能够向 UI 展示基本的健康检查。
- 提供一种明确的机制,使应用程序能够声明对另一个应用程序的依赖关系。
- 通过创建工具可以实现的标准,促进生态系统工具和 UI 之间的互操作性。
- 促进 Kubernetes 应用程序使用通用的标签和注释。
非目标
- 创建一个所有工具必须实现的标准。
- 提供一种方式,使 UI 能够显示应用程序的指标。
Katib
什么是 Katib?
Katib 是一个原生于 Kubernetes 的自动化机器学习(AutoML)项目。Katib 支持超参数调优、提前停止和神经架构搜索(NAS)。了解更多 AutoML 信息,请访问 fast.ai、Google Cloud、Microsoft Azure 或 Amazon SageMaker。 Katib 是一个与机器学习(ML)框架无关的项目。它可以调优用任何用户选择的语言编写的应用程序的超参数,并且本身支持许多 ML 框架,例如 TensorFlow、MXNet、PyTorch、XGBoost 等。 Katib 支持多种 AutoML 算法,例如贝叶斯优化(Bayesian optimization)、帕尔森估计树(Tree of Parzen Estimators)、随机搜索(Random Search)、协方差矩阵自适应进化策略(Covariance Matrix Adaptation Evolution Strategy)、Hyperband、高效神经架构搜索(Efficient Neural Architecture Search)、可微分架构搜索(Differentiable Architecture Search)等等。更多算法支持即将推出。 Katib 项目是开源的。开发者指南是希望为该项目做出贡献的开发者的良好起点。 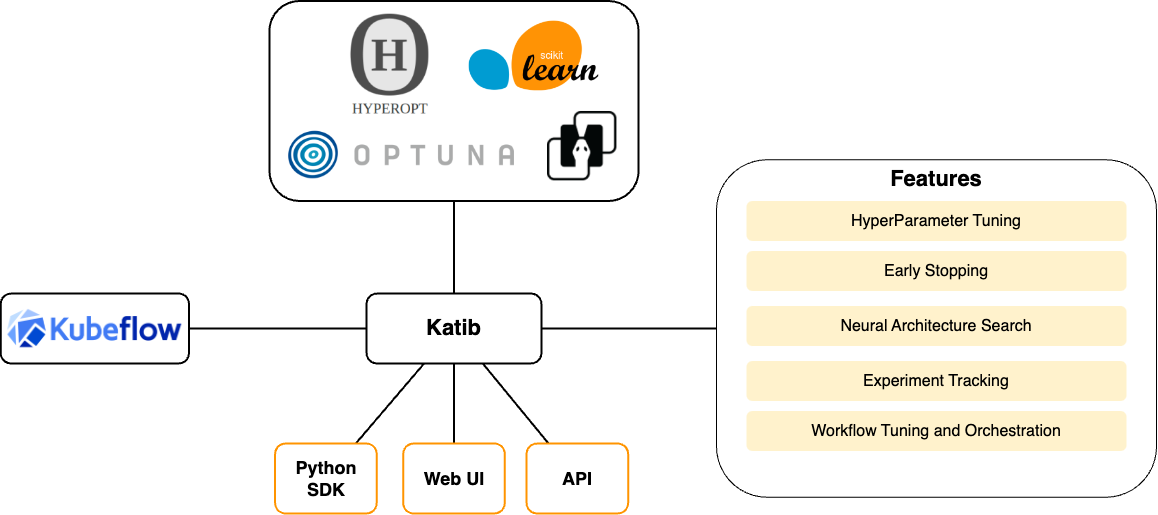
为什么选择 Katib?
Katib 解决了 AI/ML 生命周期中的自动化机器学习(AutoML)步骤中的超参数优化或神经架构搜索问题,如下图所示: 
- 多节点和多GPU分布式训练:Katib 可以协调多节点和多GPU的分布式训练工作负载。
- 与 Kubeflow Training Operator 集成:Katib 与 Kubeflow 的训练操作(如 PyTorchJob)集成,允许优化任何规模的大模型的超参数。
此外,Katib 可以协调更高级的优化工作流,如 Argo Workflows 和 Tekton Pipelines。
- 可扩展性和可移植性:Katib 是可扩展和可移植的。Katib 运行 Kubernetes 容器来执行超参数调优任务,这使得 Katib 可以与任何 ML 训练框架一起使用。
- 用户甚至可以使用 Katib 来优化非ML任务,只要能够收集优化指标。
- 丰富的优化算法支持:Katib 与许多优化框架(如 Hyperopt 和 Optuna)集成,这些框架实现了大多数最先进的优化算法。
- 用户可以利用 Katib 控制平面来实现和基准测试他们自己的优化算法。
Pipeline工作流程
pipeline服务注册流程
 其他服务注册在
其他服务注册在 startRpcServer 函数中,注册了以下服务:
API v1beta1 注册的服务
- ExperimentService: 实验服务
apiv1beta1.RegisterExperimentServiceServer(s, sharedExperimentServer)- PipelineService: 流水线服务
apiv1beta1.RegisterPipelineServiceServer(s, sharedPipelineServer)- JobService: 作业服务
apiv1beta1.RegisterJobServiceServer(s, sharedJobServer)- RunService: 运行服务
apiv1beta1.RegisterRunServiceServer(s, sharedRunServer)- TaskService: 任务服务
apiv1beta1.RegisterTaskServiceServer(s, server.NewTaskServer(resourceManager))- ReportService: 报告服务
apiv1beta1.RegisterReportServiceServer(s, server.NewReportServer(resourceManager))- VisualizationService: 可视化服务
apiv1beta1.RegisterVisualizationServiceServer(
s,
server.NewVisualizationServer(
resourceManager,
common.GetStringConfig(cm.VisualizationServiceHost),
common.GetStringConfig(cm.VisualizationServicePort),
))- AuthService: 认证服务
apiv1beta1.RegisterAuthServiceServer(s, server.NewAuthServer(resourceManager))API v2beta1 注册的服务
- ExperimentService: 实验服务
apiv2beta1.RegisterExperimentServiceServer(s, sharedExperimentServer)- PipelineService: 流水线服务
apiv2beta1.RegisterPipelineServiceServer(s, sharedPipelineServer)- RecurringRunService: 定期运行服务
apiv2beta1.RegisterRecurringRunServiceServer(s, sharedJobServer)- RunService: 运行服务
apiv2beta1.RegisterRunServiceServer(s, sharedRunServer)其他
- ReflectionService: 反射服务
reflection.Register(s)总结
在这个 startRpcServer 函数中,注册了以下 13 个服务:
- ExperimentService(v1beta1 和 v2beta1)
- PipelineService(v1beta1 和 v2beta1)
- JobService(v1beta1)
- RunService(v1beta1 和 v2beta1)
- TaskService(v1beta1)
- ReportService(v1beta1)
- VisualizationService(v1beta1)
- AuthService(v1beta1)
- RecurringRunService(v2beta1)
- ReflectionService
这些服务涵盖了实验管理、流水线管理、作业管理、运行管理、任务管理、报告生成、数据可视化和认证功能,并且支持不同版本的API。 
pipeline创建流程
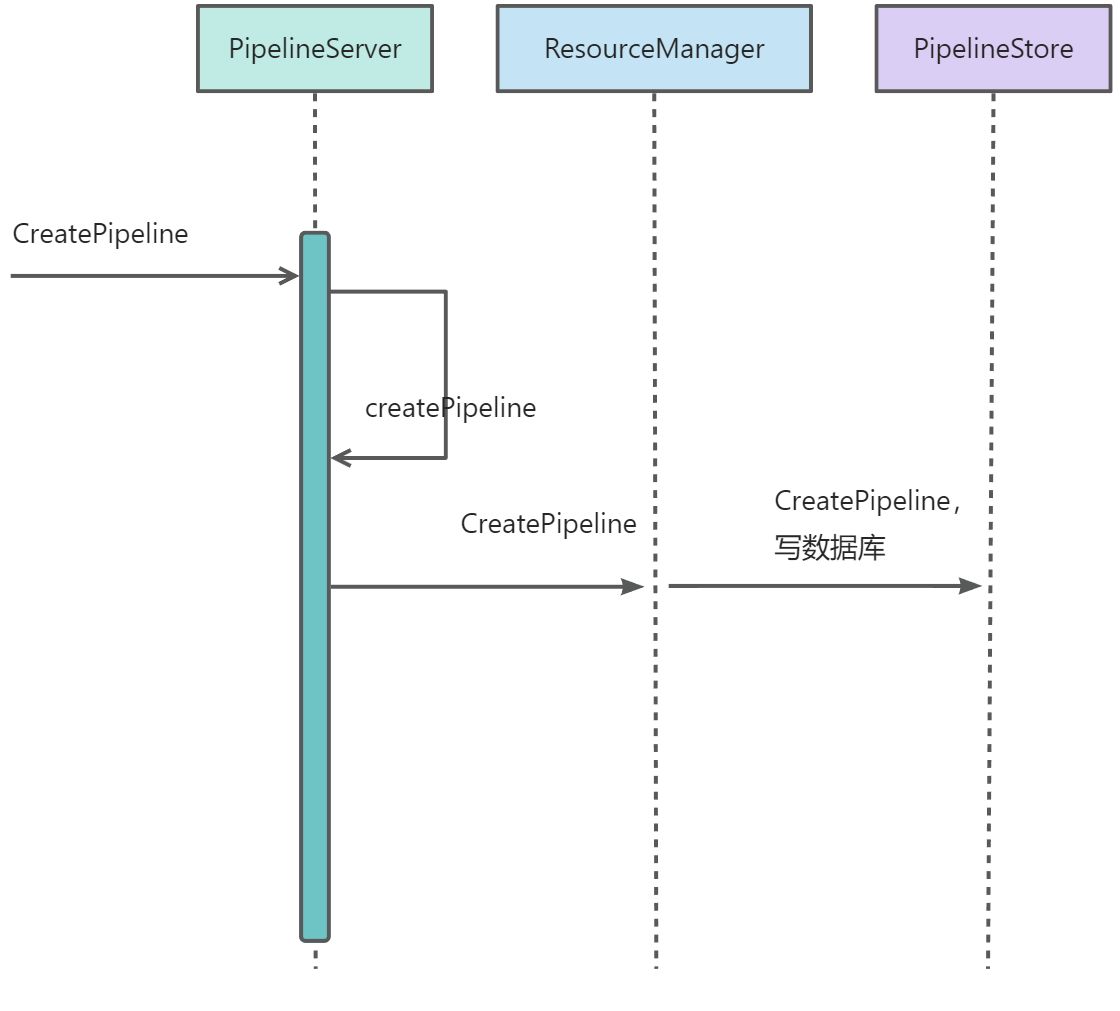 创建流水线只是把相关参数信息写入数据库。
创建流水线只是把相关参数信息写入数据库。
创建Runs
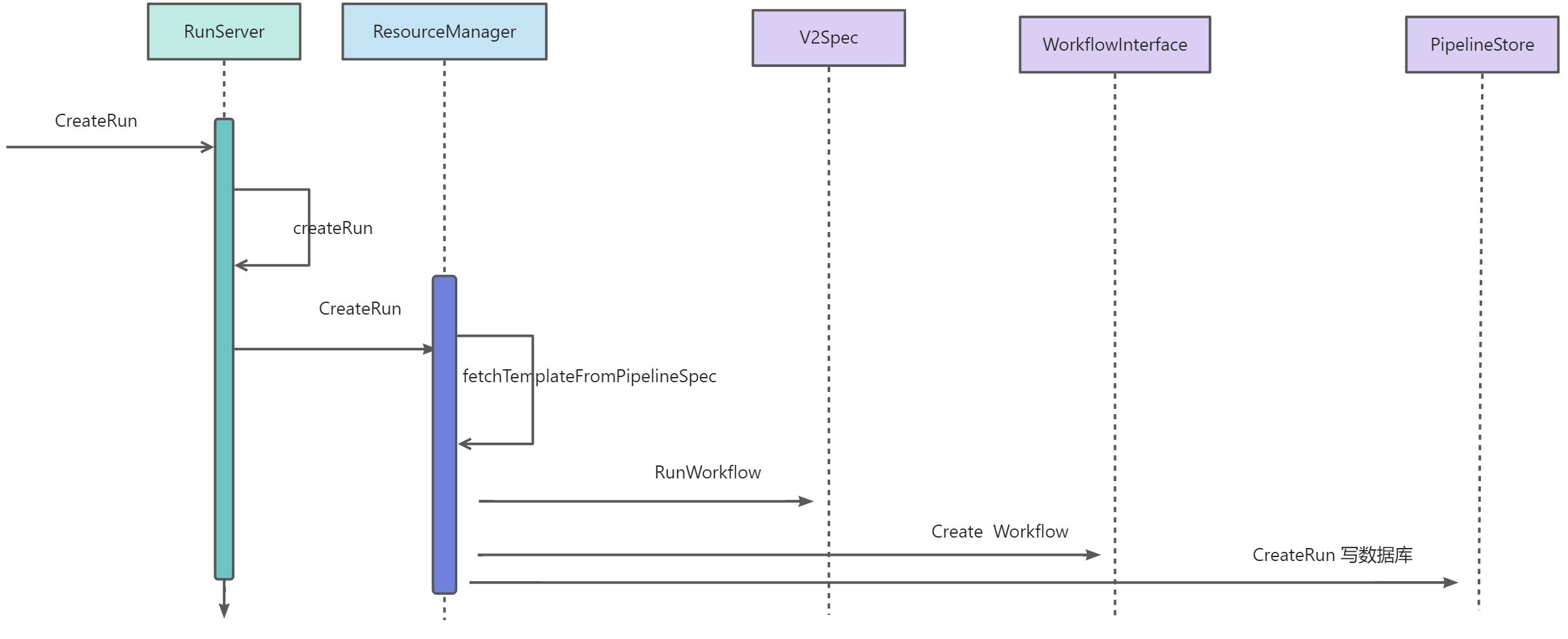 Runs创建过程是 请求apiserver->请求workflow,然后保存相关数据
Runs创建过程是 请求apiserver->请求workflow,然后保存相关数据