nnScaler:重塑深度学习并行策略,大幅提升训练效率
MPress: Democratizing Billion-Scale Model Training on Multi-GPU Servers via Memory-Saving Inter-Operator Parallelism
摘要
随着深度神经网络(DNN)模型规模的增长,深度学习训练越来越依赖手工设计的搜索空间来找到高效的并行执行计划。然而,我们的研究表明,现有的搜索空间忽略了一些重要的计划配置,这些配置在某些设置下(如处理大型嵌入表时)对著名DNN模型(例如AlphaFold2)的训练性能有显著影响。
为了解决这个问题,我们提出了nnScaler,这是一个用于生成深度学习训练并行化计划的框架。nnScaler不依赖现有的搜索空间,而是通过三个原语(op-trans、op-assign和op-order),让领域专家能够构建自己的搜索空间。这些原语能够捕捉模型的转换以及任何并行化计划中转化模型的时空调度。为了避免搜索空间爆炸,nnScaler允许在构建空间时对这些原语应用约束。通过这些原语和约束,nnScaler不仅可以构建现有的搜索空间,还可以创建新的空间。实验表明,nnScaler能够在新的搜索空间中找到并行化计划,与DeepSpeed、Megatron-LM和Alpa等解决方案相比,对一些流行的DNN模型(如Swin-Transformer和AlphaFold2)实现了最高3.5倍的加速。
1. 引言
近年来,深度神经网络(DNN)模型的规模迅速增长,训练这些模型的计算需求也随之大幅增加。为了满足这一需求,分布式训练成为了主流。分布式训练通过将计算任务分配到多个设备(通常是GPU)上来加速训练过程。这种并行化的效果依赖于如何将模型的计算操作有效地分配给多个设备,合理的分配计划可以显著提高训练性能。
然而,设计高效的并行训练计划并非易事。现有的方法通常依赖于手工设计的搜索空间,这些搜索空间定义了并行化的各种配置。然而,我们的研究表明,这些搜索空间通常不够全面,忽略了许多潜在的计划配置。这些遗漏的配置在某些情况下对训练性能有很大的影响,尤其是在处理大型嵌入表或复杂模型(如AlphaFold2)时。
为了填补这一空白,我们提出了nnScaler,一个新的框架,用于生成深度学习训练的并行化计划。nnScaler的核心思想是通过三个基本原语(op-trans、op-assign、op-order)让领域专家能够定义和构建自己的搜索空间。这些原语可以捕捉模型转换以及任何并行化计划中对模型的时空调度,从而避免了现有方法中过于狭窄的搜索空间。
nnScaler不仅可以重现现有的搜索空间,还可以创建新的搜索空间,从而探索更多潜在的并行化配置。通过在构建空间时引入约束条件,nnScaler有效地避免了搜索空间爆炸的问题。
我们的实验结果表明,nnScaler能够在这些新的搜索空间中找到高效的并行化计划,并在多个流行的DNN模型(如Swin-Transformer和AlphaFold2)上取得了显著的性能提升,最高加速达到3.5倍,优于现有的主流解决方案(如DeepSpeed、Megatron-LM和Alpa)。
2. 背景与动机
并行化计划的搜索空间。并行化计划是指一种训练执行计划,它指定了在给定的 GPU 集合上模型的分区和相应的时空调度方案。训练一个拥有数百亿参数的大型模型需要数千个 GPU。一个大型模型可能由大约 100 层组成,每一层代表一个子神经架构(例如,注意力机制),其中包含处理具有数万维度大小的张量的多个操作符(例如,隐藏维度)。对于大型模型而言,广泛的分区选择和大量的时空调度选择结合在一起,形成了一个极其庞大且组合复杂的并行化计划搜索空间。
现有的方法依赖于经过充分研究的手工并行化计划或搜索空间来解决这个问题。例如,数据并行性是一种特殊的并行化计划,它沿着与其相关的张量的批次维度对操作符进行分区。这些分区后的操作符随后在多个设备(GPU)上复制,并共享相同的模型参数(权重),以实现并发模型训练。张量并行性是一类更一般的计划,允许在不限于批次维度的维度上进行分区。这种方法允许将分区后的操作符分布在不同的设备上,以适应无法在单个设备上容纳的模型。
由于大型深度神经网络(DNN)模型通常由多个层组成,因此也可以将模型分为多个阶段,每个阶段包含一个或多个层。各个阶段被放置在不同的设备上并以流水线方式执行,因此称为流水线并行性。为了提高流水线效率,训练样本的批次进一步被划分为微批次,并按照精心设计的时间顺序执行。
上述并行化方案可以组合成一种新的方案,称为 3D 并行性,以进一步提高训练效率。Megatron-LM 集成了 3D 并行性,这种方法以参数化的方式结合了数据、张量和流水线并行性,以支持类似 GPT 的模型。给定 N 个设备,Megatron-LM 将模型分为 K 个阶段,每个阶段再分为 M 个分区。模型使用 K 阶段流水线并行性和 M 路张量并行性进行执行。对于足够大的 N,Megatron-LM 还可以采用 (N / (M * K))-路数据并行性,以进一步提高训练性能。3D 并行性代表了在大型搜索空间内几类经过充分研究的并行化计划。
Alpa 进一步将这些并行化方案进行概括,手工构建了一个两级层次化搜索空间。这个层次结构使得可以使用动态规划等高效搜索技术。由于其更大的搜索空间,即 SPMD(广义张量并行空间)和流水线并行性的结合,Alpa 被证明能够产生更优的并行化计划。
2.1 现有搜索空间的局限性
尽管现有的手工并行化搜索空间在具有相似模型架构的主流模型中显示出有效性,但它依赖于简化搜索和构建并行化计划的假设。然而,这些简化可能会排除一些有前景的计划。
在张量并行性中,假设分区后的操作符及其对应的分割张量分布在不相交的设备上。例如,为了训练具有高保真图像的视觉模型,张量并行性将与大图像相关的大型张量进行分割,并将分割后的张量分配给不相交的设备。这排除了将分割操作符放置在较少设备上的情况,即多个操作符共享一个设备,并以流线化的方式计算,以同时减少内存消耗和设备间通信成本。
流水线并行性假设训练涉及一次前向传播和一次反向传播。然而,像 AlphaFold2 这样的模型需要三次前向传播和一次反向传播。这种非常规的训练方法使得现有的流水线并行性无法适用。
流水线并行性还假设不同的流水线阶段分布在不相交的设备上,并禁止任何两个阶段通过时间复用共享相同的设备集。例如,多语言大型语言模型(LLMs)通常在模型的早期计算阶段使用一个大型嵌入表。这导致显著的 GPU 内存消耗(超过 40%),但计算利用率却很低(不到 5%)。鉴于流水线并行性(以及张量并行性)中的不相交设备分配,硬件利用率的不平衡是不可避免的。
后来的手工搜索空间(例如,结合张量和流水线并行性等的方案)继承了这些假设,因此也遭受了相同的局限性。这促使我们设计一种更灵活的空间构建方法,使领域专家能够为他们的模型找到更有效的训练计划。
2.2 由于灵活性带来的新挑战
引入一种更灵活的方式来构建并行化计划空间带来了新的挑战。现有的框架,如 Megatron-LM、Alpa 和 DeepSpeed,仅实现了一些经过充分研究的分区、调度和通信方案,这些方案支持在已知的并行化空间内的并行化计划。然而,新的空间可能会揭示操作符分区的新方法,以及具有非常规通信模式的新操作符调度。此外,更灵活的并行化计划研究较少,因此可能容易出错。
为了解决上述挑战,我们设计了一个编译过程,以检测和防止并行化计划中的潜在错误(例如,转换后的数据流图中的循环),并为发现的并行化计划生成具有高效通信操作的运行时代码。
3. 并行化搜索空间构建
并行化计划可以自然地通过模型分区和分区模型的时空调度来表达。因此,nnScaler 提出了三个原语:op-trans、op-assign 和 op-order(见表 1),以捕捉并行化计划的三个方面。将这些原语结合起来,可以为任意模型和加速器设备构建任何并行化计划的搜索空间。
op-trans
op-trans(op, algo, n) 根据选定的转换算法 algo 将操作符 op 转换为 n 个子操作符,该算法从与 op 类型相对应的算法集中选择。例如,矩阵乘法操作符 matmul(Ai,k,Bk,j) 可以沿着张量 A 的维度 i 将其分区为两个 matmul 操作符,同时复制张量 B。实际上,大多数操作符可以沿着其相关张量的某个维度(例如 A 或 B 的 i 或 k)进行分区,并且分区后的(子)操作符的计算与原始操作符的计算保持一致。
基于这一观察,nnScaler 实现了大多数深度神经网络(DNN)模型中主要操作符的分区算法。领域专家可以通过 algos() 接口重用所需的算法。nnScaler 还可以集成自定义转换算法,例如由领域专家开发的算法,适用于任何给定的操作符。需要注意的是,转换算法不仅限于操作符分区。例如,可以通过增加一个额外的重新计算操作符或内存交换操作符来增强操作符,以节省内存。在本文中,我们将“转换”和“分区”这两个术语互换使用。
op-assign
给定一组设备 D 和一个操作符 op,op-assign(op, d) 表示操作符 op 将在 D 中的第 d 个设备上执行。
op-order
当非依赖操作符(例如 op1 和 op2)被分配到同一设备时,op-order(op1, op2) 确保op1 必须在 op2 之前执行。非依赖操作符的执行顺序在训练性能中可以发挥至关重要的作用。例如,在流水线并行性中,流水线阶段中的一个操作符可以沿着批次维度分区成多个微批次。我们把这些(子)操作符表示为 op.mb1、op.mb2 等,其中 mbi 表示相应的微批次 ID。这些操作符 op.mbi 可以在任意顺序下相对于 op.mbj(i ≠ j)执行。
然而,各种研究表明,一旦这些操作符在时间维度上被精心编排,就有可能最小化流水线“气泡” [24, 54],从而显著提高训练效率。
使用上述提到的三个原语,领域专家可以编写 Python 代码来为任何深度神经网络(DNN)模型构建任意并行化计划的搜索空间。这些代码不一定与特定的 DNN 模型绑定。因此,nnScaler 将模型代码与搜索空间和搜索策略相关的代码分离。请注意,为了简化编程工作,原语中的 op 可以代表一个子图,其中原语适用于子图中的每个操作符。
由于原语的灵活性和大型 DNN 模型的规模,构建的并行化搜索空间通常包含数百甚至数千个操作符,具有组合搜索复杂性。为了解决这个问题,nnScaler 允许领域专家在应用这些原语时施加约束。这些约束可以显著减少搜索空间(第 4 节),从而使得有效的搜索方法(第 5 节)成为可能。
4. 在搜索空间中应用约束
在 nnScaler 中,约束被表达为表 1 中原语的参数化参数。当所有参数都变为具体值时,整个空间就缩减为一个具体的并行化计划。以下,我们将说明如何使用三个原语和约束(第 4.1 节)来表达像数据、张量和流水线并行性这样的经过充分研究的并行化计划。第 4.2 节讨论了导致新颖并行化计划的一些新约束。
4.1 现有搜索空间的约束
数据并行和张量并行的约束。表2显示了数据并行和张量并行相关的基本操作和约束。数据并行和张量并行都将算子均匀地分成n个部分。该分割沿某一维度进行,由algo描述,每个被分割的子算子被分配到不同的设备上并发执行,即表2中的约束2和3。注意,数据并行始终沿着批次维度进行分割,因此algo的选择比张量并行更为受限。
Table 2: Constraints for data and tensor parallelisms.
| Primitives | Constraints |
|---|---|
| 1 sub-ops = op-trans(op,algo,n) | n =| D | |
| 2 op-assign(sub-opi,di) | di,dj ∈ D |
| 3 op-assign(sub-opj,dj) | di ̸= dj |
管道并行的约束。给定一组设备D,管道并行将模型G划分为子图Gi (0 ≤ i < |D|),其中i表示第i个管道阶段。子图将被分配到不同的设备上,如表3所示。
Table 3: Constraints for dividing a model G into |D| stages
| Primitives | Constraints |
|---|---|
| 1 op-assign(Gi, di) | di,dj ∈ D, |
| 2 op-assign(Gj, dj) | di ̸= dj |
为了最小化“气泡”,管道并行将一批样本划分为多个微批次。子图(Gi,n)处理第n个微批次。我们进一步将正向子图表示为fGi,反向子图表示为bGi,著名的1F1B【24】管道并行的约束总结在表4中。
Table 4: Constraints for 1F1B schedule.
| Primitives | Constraints |
|---|---|
| 1 op-order((fGi,m),(fGi,n)) 2 op-order((bGi,m),(bGi,n)) | m < n |
| 3 op-order((fGi,m+ofst),(bGi,m)) 4 op-order((bGi,m),(fGi,m+ofst+1)) | ofst=|D| −i,m ≥ 0 |
如图 1 所示,表 4 中的约束 1 和 2 确保了以下内容:在阶段 i 中,微批次的前向和反向传播的执行顺序必须相同。也就是说,对于任何两个微批次 m 和 n,其中 m < n,fGm 应该在 fGn 之前执行(1)。同样的规则也适用于反向传播中的 bGm 和 bGn(2)。
表 4 中的约束 3 和 4 指定了 1F1B 的微妙调度顺序。它们定义了 ofst,即相对于当前阶段的偏移量。在流水线中越早的阶段,偏移量越大。因此,对于 Gi,较早的微批次的反向传播应该相对于前向传播执行得晚(3)。而较晚的微批次的前向传播应该在较早微批次的反向传播之后紧接着执行(4)。
4.2 新的约束
除了现有的搜索空间之外,领域专家可以应用新的约束来构建自定义的搜索空间,以便为各种模型搜索新的、更高效的并行化方案,具体说明如下。
4.2.1 Swin-Transformer 的约束
为了提升视觉任务的能力,越来越多的人选择采用更高分辨率的图像来训练大型视觉模型,例如 Swin Transformer。使用更大的图像会在训练过程中生成更大的中间张量,尤其是在注意力 (Attn) 和前馈 (FF) 算子中。这要求比单个 GPU 更大的内存才能容纳这些数据。
张量并行是解决此问题的标准做法。对于一个流水线来说,Attn 和 FF 中的算子被分割并分配到 |Mi| 台设备上,Mi 是设备集,用于容纳第 i 阶段中的算子。张量并行分割的算子被放置在不同的设备上,因此每个设备只持有一个分割后的算子。然而,我们观察到,有时多个分割后的算子可以共享一个设备,从而以流水线方式进行计算,减少每个阶段所需的设备数量并降低内存消耗。尽管多个分割算子的流水线计算可能会减慢计算过程,但减少设备间的通信可以降低成本并加快整体过程。
在阶段 i 中的任意 Attn 和 FF 算子 op 中,设 sub_op 为 op 任何一个经过转换的子算子。假设允许 C 个子算子共享一个设备,从而导致一个设备集 Di 被分配给第 i 阶段的算子,其中 |Di| < |Mi|。这些约束如表 5 所示。其他算子可以通过现有的搜索空间来描述,即文献 [65] 中定义的搜索空间。注意,C 是一个超参数,其值可以通过策略搜索确定(详见第 5 节)。
4.2.2 T5 的约束
多语言模型如 T5 通常使用一个大型嵌入表 E,其中包含来自多种语言的词汇嵌入。E 只在 LLM 的第一个和最后一个层中使用,但它消耗了大量内存,计算成本却很低。管道并行会优先考虑分配设备以容纳 E,并将其余设备留给其他算子。这种安排会导致硬件利用率不平衡,包含 E 的设备 GPU 周期使用率很低,而内存使用率却很高。
通过 nnScaler 提供的三个原语和约束,我们可以将 E 拆分到整个设备集 D 上。然后通过构建遵循常规搜索空间的搜索空间,其他算子可以共享 D 中剩余的资源。这些约束在表 6 中有突出体现,它打破了不同流水线阶段中的算子不能共享同一设备集的常规假设。类似的解决方案也适用于图神经网络的训练。
4.2.3 AlphaFold2 的约束
在 AlphaFold2 中,每个微批次的训练需要三个前向传播和一个反向传播(即 3F1B)。传统的 1F1B 流水线并行无法支持这种模式。图 2 左侧显示了训练一个微批次后再训练另一个的朴素方法,这种方法由于流水线气泡和中间结果的积累效率低下。因此,我们决定在不同微批次中交错前向和反向传播,同时保持时间顺序上的约束。设 fpGi 表示第 i 个流水线阶段中的第 p 次前向传播子图,ofst 为 S-i,其中 S 表示流水线阶段的总数。表 7 中列出了 3F1B 的约束条件。
表 7 中的约束 1 和 2 交错了连续微批次的三个前向传播,顺序为递减。约束 3 规定,在最后执行的前向传播完成后,对应的反向传播子图应该在具有相对当前阶段的偏移量(ofst)的微批次ID上执行。
4.3 讨论
约束是定制各种并行化计划并定义其搜索空间的强大抽象工具。为了设计有效的约束,nnScaler 假设其用户,通常是领域专家,对模型架构和并行训练具有深入了解。有了这些知识,使用三个原语构建搜索空间就变得直观了。根据我们的经验,可以通过识别训练中的性能瓶颈(例如,过高的 GPU 内存使用、计算/通信不平衡)来推导出有效的约束。然后可以定义这些约束以缓解瓶颈。此外,随着约束调整后瓶颈的变化,约束可以迭代地细化。通过对约束的细化,nnScaler 使并行化计划的生成比以前的方法更加简单。
5. 计划搜索策略
有了新的用户定义搜索空间后,nnScaler 引入了一个通用的策略框架来搜索高效的并行化计划。如算法1所示,策略将模型图 G 和用户指定的搜索空间作为输入。我们将搜索空间表示为 Ctrans、Cassign 和 Corder,它们分别对应三个原语:op-trans、op-assign 和 op-order,并带有与约束相关的增强。策略通过逐渐收紧约束来缩小空间,最终将其减少到唯一的并行化计划,即 Cfinal_trans、Cfinal_assign 和 Cfinal_order。
策略框架的一个关键特点是,它允许开发者从新的搜索空间中“切割”出一个子空间,在这个子空间中可以应用现有的搜索策略。具体来说,搜索过程包括两个阶段:算子划分与放置搜索,以及时间顺序搜索。
5.1 算子划分与放置搜索
这一阶段的目标是将计算均匀分配到多个设备上,同时最小化通信成本。一个算子的不同划分选项会带来不同的通信成本。例如,划分批次维度需要对参数执行全归约操作,而划分参数则需要在设备间复制输入激活张量。算子的不同放置选项也会导致各设备执行时间不同。因此,一个设备 d 上的执行时间为其分配的算子的计算时间 Compd 与相关通信时间 Commd 之和。整体运行时间由最慢的设备决定。
minimize max {Compd + Commd}通过将划分和放置选项表示为整数,这个优化问题可以被看作是一个 NP 困难的整数线性规划问题。应用约束后,公式中的搜索空间可以大大缩小,从而加快搜索过程。
5.2 时间顺序搜索
在算子变换与分配完成后,某些算子的时间顺序已由转换后的图中的数据依赖关系确定。然而,同一设备上的两个没有直接依赖关系的算子可以以任意顺序执行。此外,对于流水线并行,同一批次中的不同微批次上执行的同一算子的顺序未被指定。nnScaler 利用 Tessel,一个最先进的搜索策略来确定这些算子的执行顺序。
6. 并行化计划的编译
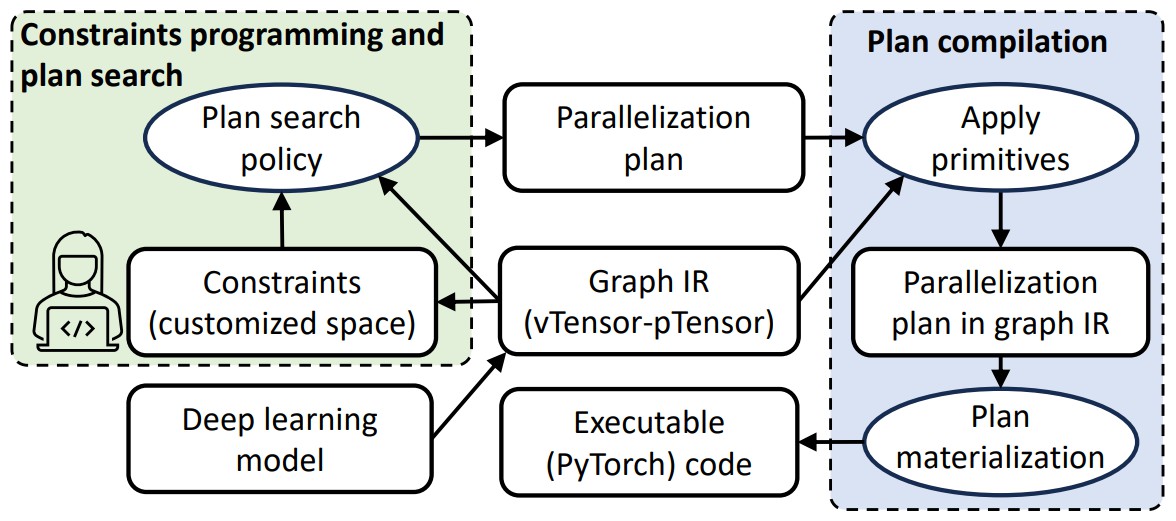
nnScaler 会将模型和生成的并行化计划编译为可执行代码,遵循图 3 中展示的端到端流程。系统首先将深度学习模型转换为数据流图(Graph IR)。通过原语和相关约束定义搜索空间,nnScaler 利用搜索策略生成并行化计划。计划编译接着将该计划定义的原语和约束应用于 Graph IR。在此步骤中,nnScaler 通过 vTensor 和 pTensor 抽象进行数据依赖追踪。生成的新数据依赖关系以及由于算子分布到多个设备而产生的额外通信操作会被反映到 Graph IR 中,最终这些内容会被物化为并行执行的可执行代码。
张量抽象 vTensor 和 pTensor
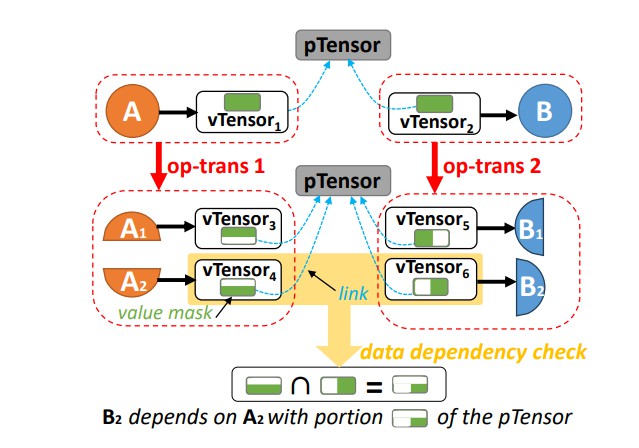 vTensor 和 pTensor 被引入以追踪应用三个原语时数据依赖关系的变化。如图 4 所示,pTensor 表示逻辑模型中的张量,而 vTensor 则表示应用原语后产生的结果张量。vTensor 连接到 pTensor,并维护一个掩码,指示该 vTensor 所代表的 pTensor 部分。一个 pTensor 可以与多个算子相关联。在图 4 的顶部,算子 A 的输出作为算子 B 的输入,两个算子通过各自的 vTensor 连接到同一个 pTensor。
vTensor 和 pTensor 被引入以追踪应用三个原语时数据依赖关系的变化。如图 4 所示,pTensor 表示逻辑模型中的张量,而 vTensor 则表示应用原语后产生的结果张量。vTensor 连接到 pTensor,并维护一个掩码,指示该 vTensor 所代表的 pTensor 部分。一个 pTensor 可以与多个算子相关联。在图 4 的顶部,算子 A 的输出作为算子 B 的输入,两个算子通过各自的 vTensor 连接到同一个 pTensor。
通过 vTensor,每个算子都可以独立地进行变换、分配和排序。当应用 op-trans 时,nnScaler 通过 vTensor 的“掩码”划分 vTensor,而 pTensor 保持不变。例如,在图 4 中,算子 A 只会拆分自身及其输出的 vTensor,而算子 B 的 vTensor 不受影响。对于其他类型的原语,vTensor 的掩码保持不变。因此,nnScaler 可以通过计算生产者和消费者 vTensor 的掩码交集来检测它们之间是否存在数据依赖关系。运行时执行过程中,只有 vTensor 会被实例化为实际的 GPU 张量实例。
借助 vTensor-pTensor 抽象进行数据流图转换时的依赖追踪,nnScaler 能够检测到新生成的图中的循环依赖,从而避免出现死锁,确保计划的有效性。
数据依赖的物化
在应用了原语和约束后,nnScaler 将通过 vTensor-pTensor 物化新的数据依赖关系为具体的数据操作和通信操作。对于消费者 vTensor(如图 4 中的 B1),nnScaler 会识别出依赖的生产者 vTensor(如 A1 和 A2),并在物化过程中插入张量操作(例如 torch.split 或 torch.chunk)以提取相应的张量片段。当生产者和消费者位于不同设备上时(由于 op-assign 的作用),nnScaler 会在物化过程中插入点对点的发送-接收通信操作。
为了提高通信效率,位于同一 pTensor 下的 vTensor 之间的某些通信模式可以通过集体通信原语(如 allgather、allreduce 或 alltoall)来实现。例如,图 4 中,A 的 vTensor3 和 vTensor4 与 B 的 vTensor5 和 vTensor6 之间的通信可以通过更高效的 alltoall 原语来物化。nnScaler 使用简单的模式匹配来识别每个 pTensor 及其相关 vTensor 的适当集体通信原语。
7. 实现与经验
我们基于 PyTorch 实现了 nnScaler,代码量达到了 24,000 行 Python 代码。nnScaler 读取为单设备开发的 PyTorch 模型,并将其转换为中间图表示 (IR)。在进行转换、时空调度以及插入通信和张量操作后,每个设备将接收一个由 IR 表示的子图。nnScaler 然后将这些子图转换回 PyTorch 代码文件,并通过 torchrun 并行执行以进行分布式训练。
为了支持各种 PyTorch 模型,nnScaler 基于 TorchFX 实现了增强的图转换器,包含 2,243 行 Python 代码。该转换器结合了 TorchFX 的符号执行和 torch.jit.trace 的值跟踪来处理控制流,这是将 PyTorch 模型转换为 TorchFX 时的典型障碍。默认情况下,PyTorch 模型通常只包含前向传播,nnScaler 自动使用链式法则的 autograd 功能完成反向传播。到目前为止,nnScaler 已成功转换了 HuggingFace 自然语言处理任务中的 84.1% 的 PyTorch 模型。转换失败的原因主要是由于某些不支持的算子(例如为特定模型设计的自定义算子)。我们正在积极探索支持更多算子及其对应的转换算法的方法。
7.1 实践经验
nnScaler 已被 Microsoft 不同团队的多个项目使用,用于支持多代 NVIDIA 和 AMD GPU 上的下一代 DNN 模型的预训练和微调。这些模型包括 RetNet、YOCO、LongRoPE、Phi-3 系列以及一个由 Transformer 和图神经网络(GNN)组成的大型科学基础模型,模型参数范围从 30 亿到 920 亿不等。
选择使用 nnScaler 的决定主要基于两个关键因素。首先,将新模型整合到现有的分布式训练框架中通常会遇到复杂的工程挑战,包括新模块的并行化、适当的划分选项以及确保端到端训练的正确性。这个过程通常需要两名有经验的工程师大约两个月的时间才能完成。此外,现有的并行化方案往往在新模型上表现不佳,导致模型 FLOPs 利用率 (MFU) 不理想。其次,研究新模型通常需要更改模型架构、配置和训练设置,这可能需要进一步调整并行化计划以提高训练效率。nnScaler 正是为了解决这些问题而设计的。
此外,我们与这些团队的合作也带来了许多启示。
7.1.1 调试 nnScaler
nnScaler 在模型训练中提供了很大的灵活性,但新的原语和约束也增加了系统的复杂性,使某些并行化计划容易出错。为了解决这个问题,nnScaler 采用了一种模块化的调试方法,允许将由新约束生成的较少研究的子图替换为经过充分测试的约束。例如,nnScaler 可以选择性地将数据并行性应用于模型的一部分,而其余部分保持现有的并行化计划不变。此调整不需要修改模型代码,只需重新配置预构建的并行化计划。通过迭代地更改计划中疑似有问题的模块,这种方法有助于定位问题模块。
7.1.2 模型准确性
实现高模型准确性是训练的最终目标。然而,有时训练框架或模型代码中的一个小错误就会导致准确性下降。更复杂的是,在训练早期阶段,系统可能表现正常,但经过数千步的训练后,损失曲线可能恶化,最终出现发散。直接将损失和梯度值与经过充分测试的训练计划(如数据并行性)进行比较是不现实的。例如,在更复杂的计划中,诸如矩阵乘法 (matmul) 或全归约 (allreduce) 操作会因不同的加法顺序导致浮点值漂移,这是预期的行为。这使得很难分辨是预期中的数值偏差,还是语义错误。
为了解决这个问题,nnScaler 首先通过减少模型的隐藏维度,使其适应单个设备的训练,从而简化调试过程。由于模型代码与训练代码之间的清晰分离,这种模型更改可以很容易实现。接下来,我们将搜索到的并行化计划应用于简化后的模型,并通过比较损失曲线和梯度归一化曲线来评估其与数据并行训练的重叠情况。我们观察到,梯度归一化曲线是一个良好的指标,能够在早期放大偏差并预示系统中潜在的错误。
7.1.3 就地操作符
为了提高训练性能,像 Tensor.add_ 这样的就地操作符会在原地更新张量。然而,对就地操作符进行划分可能会带来问题。例如,如果就地操作符的划分导致张量被克隆,而原本应在原地更新的操作变成了非就地操作,结果就不会保留原来就地操作符的效果。这是因为在混合使用就地操作符和非就地操作符时,会违反静态单一赋值 (SSA) 形式。为了避免这个问题,nnScaler 在图转换过程中遵循 SSA 规则,并在后期优化阶段将某些非就地操作符替换为原始的就地版本。
8. 评估
对 nnScaler 的评估涵盖了并行化原语的表达能力以及带有约束的并行化计划搜索效率。更重要的是,我们对实际模型的性能进行了评估,以展示整个系统在实现新模型和设置的高效并行化方面的有效性。总结来说,评估结果表明:
- nnScaler 中的并行化原语可以构建各种并行化计划,包括现有的手工设计的计划(§8.1)和本文中介绍的创新计划(§8.2)。
- 对 SwinTransformer、T5 和 AlphaFold2 的三个新并行化计划进行的端到端评估,显示它们相较于 Megatron-LM 、Alpa 、DeepSpeed 和 DAP 基线方案分别加速了 3.5×、2.5× 和 1.4×(§8.3)。
- 带有约束的并行化空间帮助 nnScaler 快速发现高效计划,搜索速度提高了 11.7×,相比于无约束的搜索。
8.1 计划构建的表达能力
我们通过实现表 8 中列出的流行手工并行化计划,评估了三种原语在计划构建中的表达能力。这些计划可以分解为操作符转换、放置和排序,与表 1 中的三种原语紧密对齐。nnScaler 成功支持了 17 个并行化计划中的 14 个。
在 SPMD(单程序多数据)下的并行化计划是通过操作符转换实现的。数据并行性和灵活的张量并行性可以轻松支持。Transformer 并行性和 DAP 是为 Transformer 和 AlphaFold2 手工设计的张量并行性。序列并行性和 ZeRO stage-3 是特殊的张量并行性,它们解耦了操作符及其输入张量的划分,以优化内存使用。nnScaler 通过在输入张量和其操作符之间插入一个恒等操作符,通过操作符转换轻松实现了这种解耦。
MPMD(多程序多数据)下的并行化计划是不同类型的手工流水线并行化。它们可以使用操作符排序来支持,无需实现新的执行引擎。值得注意的是,nnScaler 不支持 PipeDream,因为它采用的是异步训练方法,而 nnScaler 尊重模型的原始训练语义。对于 TeraPipe,nnScaler 目前缺乏访问张量中具体值的能力,因此无法在令牌级别确定数据依赖关系(即张量掩码),这是 TeraPipe 的一个要求。未来,nnScaler 可以通过深度学习模型的检测工具来实现 TeraPipe。
除了并行化之外,nnScaler 还支持内存优化技术(如重计算、交换)和计算与通信的重叠。对重计算的支持依赖于操作符转换的自定义算法 .
8.2 计划搜索结果
8.2 计划搜索结果
根据第 4.2 节描述的新约束,nnScaler 在每个构建的空间内进行搜索,并发现了三种在训练性能上表现优越的并行化计划。
Coshard:图 5 展示了 Coshard 计划,适用于像 SwinTransformer 这样包含大张量的模型。它可以与张量并行共存,以减少激活张量的峰值内存。例如,A1 被分割成两部分,放置在同一个设备上,并顺序执行。应用 A1 的重计算后,A1 的峰值激活大小减少了一半。由于峰值内存的减少,张量并行现在可以跨越更少的设备(例如,从 8 路减少到 4 路),从而降低通信成本。
交错流水线:图 6 显示了在表 6 中指定约束下搜索到的流水线调度。嵌入层通过张量并行划分到四个设备上,剩余的非嵌入层组件则根据 staged_spmd 分配到不同的设备组。在排序搜索过程中,所有层组合成一个调度,该调度类似于执行嵌入层和 1F1B(一次正向传播一次反向传播)的时间共享模式。由于调度搜索,流水线能够在没有“气泡”的情况下达到稳定状态,如图右侧所示。
3F1B 流水线:图 2 展示了第 4.2 节描述的 3F1B 流水线的时间轴。表 7 中概述的约束定义了正向和反向传递如何在流水线的稳定状态中交错执行。
8.3 端到端性能
我们分别在 SwinTransformer、T5 和 AlphaFold2 上对三种新并行化计划进行了评估,涵盖不同的模型配置和 GPU 数量。
8.3.1 实验设置
机器配置:我们的评估在配备 32 个 NVIDIA Tesla V100(32GB)的 DGX-2 集群上进行。每台服务器配备 16 个 GPU,使用 NVLink 互联。服务器之间通过 8 个 100 Gbps 的 InfiniBand 网络适配器互联。所有服务器均安装了 NCCL 2.14 和 PyTorch v2.0.1。
模型配置:我们在 SwinTransformer、T5 和 AlphaFold2 的四种不同模型配置下进行实验,从小模型到大模型不等。每个配置都包含参数数量、层数、隐藏维度和头数。
基线系统:我们将 nnScaler 与三个流行的分布式训练系统进行了比较:
Megatron-LM:专为训练基于 Transformer 的模型设计,结合了流水线并行、数据并行和张量并行的三维并行化方式。对于流水线并行,它将模型层均匀划分为多个阶段,每个阶段可以进一步应用数据并行和张量并行。当 GPU 数量足够多时,Megatron-LM 还可以使用 路数据并行来进一步提高训练性能。
Alpa:一个针对深度学习模型的自动并行化系统,基于 TensorFlow,使用三维并行化空间。它的搜索算法和训练系统目前基于 TensorFlow。为了进行直接比较,我们在 nnScaler 中实现了 Alpa 的搜索算法,作为一种策略。
DeepSpeed:与 Megatron-LM 类似的分布式训练系统,支持流水线并行、数据并行和张量并行。此外,DeepSpeed 集成了 ZeRO 和 ZeRO-Offload 等技术,以优化 GPU 内存使用。ZeRO 主要通过在数据并行模式下只保留优化器状态的单份拷贝来减少内存占用,而 ZeRO-Offload 则将权重卸载到 CPU 内存,从而减轻 GPU 的内存压力,并在需要时将其取回。
Megatron-LM 和 DeepSpeed 都不具备在其支持的并行化空间内自动搜索并行化计划的功能。因此,我们通过分别遍历流水线并行、张量并行和数据并行的不同程度,手动找到了它们的最佳性能计划。在接下来的所有实验中,我们应用了逐层重计算【11】,以减少激活张量的内存消耗。按照常见做法【29, 65】,我们使用了累计的有效 TFLOPS 作为性能指标。
8.3.2 SwinTransformer 的结果
图 7 展示了 SwinTransformer 在四个系统上的端到端训练吞吐量。由于激活张量的体积巨大(例如,一个 50 亿参数模型的第一个 Transformer 层的激活张量占用 21GB),即使应用了重计算,Megatron-LM 和 Alpa 也对所有模型配置使用了纯张量并行性。DeepSpeed 采用了 ZeRO-Offload 和 ZeRO stage 3 来优化内存使用,因此它能够在 4 个 GPU 设置中应用 2 路张量并行性,并在其余三种设置中应用 4 路张量并行性。为了扩展到所有可用的 GPU,还进一步应用了数据并行性。nnScaler 在 SwinTransformer 的前四层(Attention + MLP)上应用了 Coshard 计划,因为这些层由于激活张量占用了大量内存。nnScaler 分别对四种配置应用了 2 路、2 路、4 路和 8 路张量并行性,并分别结合了 2 路、4 路、4 路和 4 路流水线并行性。在 8 路 GPU 设置中,Coshard 对每个 GPU 顺序执行 6 个分区,而在其余三个设置中执行 4 个分区。
如图 7 所示,nnScaler 在 8、16 和 32 个 GPU 上的速度分别比 DeepSpeed 快 1.2 倍、1.5 倍和 1.5 倍。
8.3.3 T5 的结果
图 8 展示了 T5 的端到端训练吞吐量。对于 4 个 GPU,Megatron-LM 使用了 2 路张量并行性和 2 路流水线并行性,而对于 8、16 和 32 个 GPU,它只使用了纯张量并行性。Alpa 对于 4 个 GPU 使用了 3 路流水线并行性,且中间阶段应用了 2 路张量并行性。由于内存消耗较大,Alpa 必须在 8、16 和 32 个 GPU 上使用纯张量并行性。因为 T5 模型参数较小(3.9B),DeepSpeed 在 4 个 GPU 上可以使用数据并行性结合 ZeRO stage 3。在 8、16 和 32 个 GPU 上,它采用了 4 路张量并行性,并结合了 ZeRO-Offload 和 ZeRO stage 3。此外,还进一步应用了数据并行性扩展到所有可用 GPU。nnScaler 则应用了交错流水线,使用张量并行性处理大嵌入层,其他层则通过 4 路流水线并行性进行处理,每个阶段分别应用了 1 路、2 路、4 路和 8 路张量并行性,分别对应 4、8、16 和 32 个 GPU。
nnScaler 在 8、16 和 32 个 GPU 上的表现分别比 DeepSpeed 快 1.5 倍、1.6 倍和 2.5 倍。
8.3.4 AlphaFold2 的结果
图 9 显示了 AlphaFold2 的端到端训练吞吐量。在这个实验中,我们与两个基线进行了比较。一个是专门为 AlphaFold2 设计的手工张量并行方案 DAP(Deep Analysis Pipeline)。我们还应用了数据并行性来扩展 DAP,称为 DAP+DP。对于 4 和 8 个 GPU,DAP+DP 使用了纯数据并行性,因为模型较小。对于 16 个 GPU,它使用了 4 路张量并行性结合 4 路数据并行性。另一个基线是 DeepSpeed。由于 AlphaFold2 的模型尺寸比 SwinTransformer 和 T5 小得多,不需要使用 ZeRO-Offload。DeepSpeed 对于 4、8 和 16 个 GPU 使用了纯数据并行性结合 ZeRO stage 3,对于 32 个 GPU 使用了 2 路张量并行性和 16 路数据并行性。nnScaler 也在 4 和 8 个 GPU 上使用了纯数据并行性,而在 16 和 32 个 GPU 上应用了 3F1B 流水线。对于 16 个 GPU,nnScaler 使用了 4 路流水线并行性结合 4 路数据并行性;对于 32 个 GPU,它使用了 2 路张量并行性、2 路流水线并行性和 8 路数据并行性。
nnScaler 在 16 个 GPU 上比 DAP+DP 提高了 1.5 倍的性能,在 32 个 GPU 上比 DeepSpeed 提高了 1.1 倍的性能。
8.3.5 性能较低硬件上的实验
为了验证新并行化计划的有效性,并了解不同硬件对训练性能的影响,我们在 DGX-1 集群上对 SwinTransformer 和 AlphaFold2 进行了评估。图 10a 显示了 nnScaler 在 16 和 32 个 GPU 上分别比 DeepSpeed 快 1.9 倍和 3.5 倍。相比于图 7 中的数据,对于 32 个 GPU,nnScaler 的性能下降了 6%,而 DeepSpeed、Alpa 和 Megatron-LM 的性能分别下降了 60%、82% 和 82%。nnScaler 的性能下降较小,因为它使用的 Coshard 并行化计划优化了通信成本,能够适应通信带宽的变化。图 10b 显示了 AlphaFold2 在 DGX-1 上的结果。nnScaler 相对于 DeepSpeed 的相对性能增益在 16 和 32 个 GPU 上分别提高到 1.1 倍和 1.4 倍。
8.4 带有约束的搜索效率
算法 1 表明,nnScaler 中并行化计划的搜索成本包括:(1)操作符转换和放置的成本(即算法 1 中的第 1-4 行),以及(2)操作符时间排序的成本(即第 5 行)。图 11 展示了端到端搜索成本以及三种自定义空间(定义于第 4.2 节)的搜索时间细分。对于不同的模型配置,搜索策略如第 5 节所述。SwinTransformer 的搜索时间小于 150 秒。随着模型尺寸增加,操作符数量增加,搜索时间也相应增加。T5 的排序搜索时间约为 150 秒,因为 T5 的空间中没有约束条件。对于 SwinTransformer 和 AlphaFold2 来说,几乎没有排序搜索的成本。对于 SwinTransformer,顺序基本上由数据依赖关系决定;对于 AlphaFold2,排序约束大大减少了搜索空间。
图 12 进一步展示了 3F1B 调度在有约束和无约束情况下的时间排序搜索时间。左图显示,随着阶段数量的增加,搜索时间呈指数级增长。然而,应用约束后,搜索时间保持在 60 秒以内,从而在 4 个阶段的时间排序中实现了 11.7 倍的加速。这归因于表 7 中的时间排序约束,明确规定了来自不同微批次的独立正向和反向操作符的顺序,从而显著减少了搜索算法(如 Tessel)需要处理的搜索空间。
对于 4 个阶段的情况,右图进一步展示了每个来自表 7 的排序约束逐个应用时的搜索时间。第一个约束将搜索时间减少了 100 秒,第二个约束进一步将搜索时间减少了 50%。这表明了约束的重要性。